高级计算机架构(五):现代分支预测从GShare到TAGE的演进之路
发布于 • 作者: Ethan
处理器前端最难的一件事,不是把指令取出来,而是要在结果还没出来之前,先决定下一步往哪走。分支一旦猜错,流水线就要回滚,前面抢跑出来的工作都会白做。真正优秀的分支预测器,做的不是“碰运气”,而是在有限的硬件预算里,尽可能抓住程序行为里的规律:哪些分支和自己的过去有关,哪些分支和别的分支有关,哪些规律很短,哪些规律要看很长的历史才能显现。
这条演进路线很清楚:先从“记住某个分支自己的历史”开始,再走向“利用全局历史”,接着想办法减少冲突、组合多个预测器,最后发展到今天依然非常强的 TAGE。
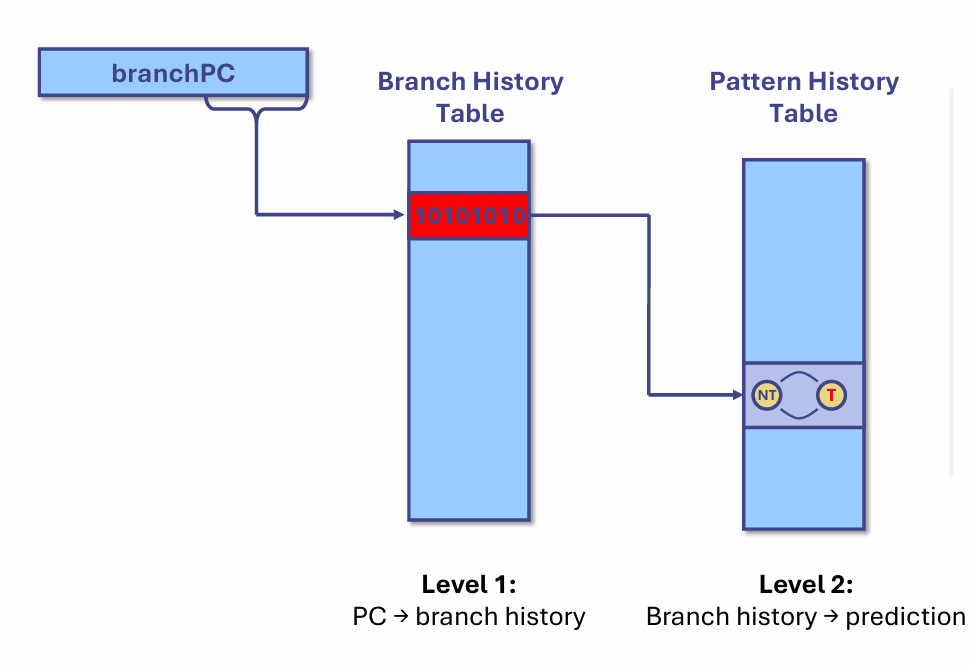
最经典的起点,是两级相关预测器(two-level predictor)。它的思路并不复杂:先根据分支的 PC 找到这条分支过去一段时间的行为历史,再用这段历史去查一张模式表,得到这次该预测 Taken 还是 Not Taken。
也就是说,预测分成两步。第一步是“PC → 历史”,第二步是“历史 → 预测”。第一层通常保存某条分支最近几次的结果,第二层的模式历史表则学习“看到这种历史模式时,下一次大概率会怎样”。这种结构的价值在于,它不再把每条分支都当成独立、无记忆的事件,而是承认很多分支是有重复模式的,比如循环末尾常常会呈现某种固定节奏。
但只看某个分支自己的过去,仍然不够。程序里很多分支之间是有关联的:前面一条条件分支改写了变量,后面另一条分支的真假就会跟着变。只盯住“我自己之前是 T 还是 NT”,经常抓不住这种跨指令的相关性。
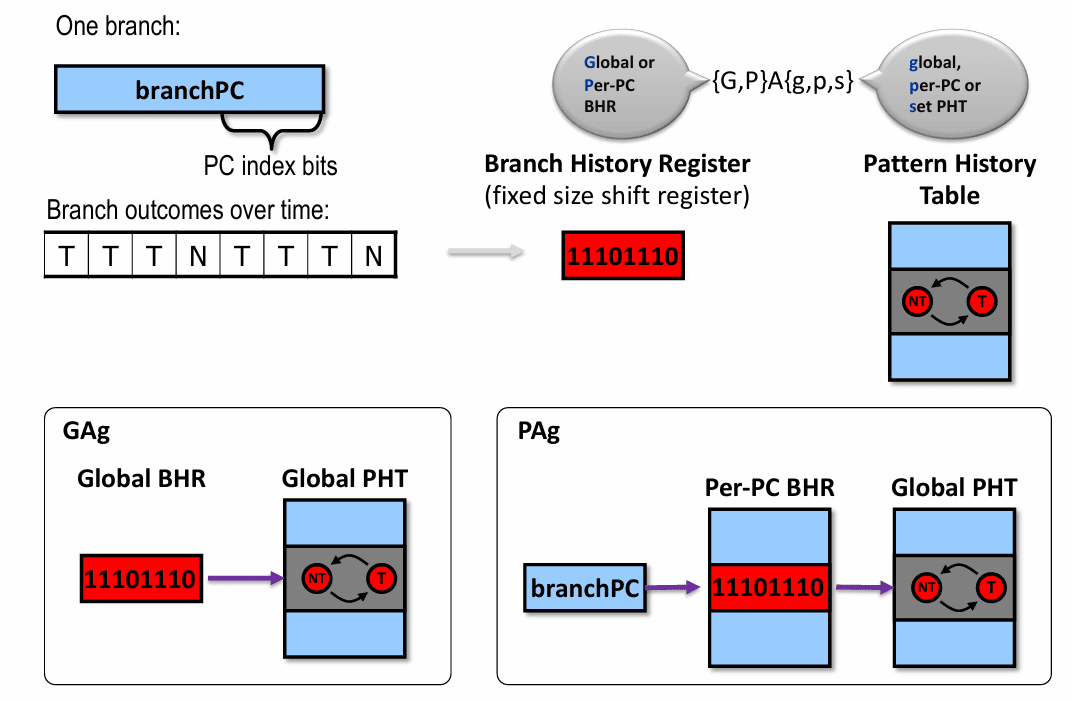
于是,全局分支预测器开始把所有分支的结果都依次移进一个全局分支历史寄存器(Global BHR, GBHR)。接下来要预测新的分支时,不再只看它自己的局部历史,而是看“最近整个程序路径上发生过什么”。这让预测器可以学到跨分支的关系,尤其适合那种“前面若干条件共同决定后续分支”的代码。
不过,全局历史带来一个很现实的问题:它必须在下一次预测之前就先更新,所以前端往往需要做推测式更新。这样一来,如果后面发现某次分支其实猜错了,就不仅要纠正控制流,还得把历史寄存器甚至相关表项的更新一起撤销或修复。分支预测从这里开始,已经不只是“怎么猜”,还变成了“怎么在推测执行里维持一致性”。
分支预测器的设计,核心上一直围绕三个问题打转。
第一个问题是:历史到底该是全局的,还是每个分支各记各的。局部历史能精确描述某一条分支自己的重复模式,全局历史则更擅长捕捉跨分支相关性。很有意思的是,全局历史并不只对“跨分支关联”有用,在很多紧凑循环里,它也能顺手把局部重复模式编码进去,因此常常比直觉里更强。
第二个问题是:历史要记多长。历史越长,理论上能看到的模式越丰富;但现实里,历史一长,状态空间就会迅速膨胀,很多模式根本不会出现,表项利用率下降,训练也会变慢。更糟的是,大量分支其实并不依赖那么长的历史,你给它很长的上下文,得到的并不是更聪明的预测,而是更多噪声。所以实际设计里,历史长度通常不会无限加大,而是会控制在一个相对务实的范围内,常见做法大约在 8 到 12 位附近。
第三个问题是:模式历史表要不要按分支拆开。把表做成每个分支私有,当然能减少互相干扰,但存储代价非常高;做成全局共享,又会让不同分支挤进同一批表项里,彼此污染。后面很多著名设计,本质上都在和这种“共享带来的冲突”较劲。
为了描述这些组合,分支预测里形成了一套常见缩写。像 GAg、PAg、GAs、PAs 这样的名字,本质上是在说明两件事:历史是全局的还是按分支保存的,模式表是全局共享的还是分组/分支私有的。从建模角度看,这类预测器也很像简化后的 Markov 预测器:它不试图记住无限长的完整过去,而是把“当前历史状态”当成预测下一次结果的依据。
如果说两级预测器教会了处理器“要看历史”,那 GShare 做的事,就是把“历史”和“当前这条分支是谁”用一种非常便宜的方式揉到一起。
GShare 的做法很直接:把分支 PC 的一部分位和全局历史寄存器做 XOR,然后拿结果去索引模式历史表。这样一来,它既利用了全局历史,又保留了按地址区分分支的能力,而且不需要真的维护一套按分支划分的历史表,硬件代价低,访问路径也短。
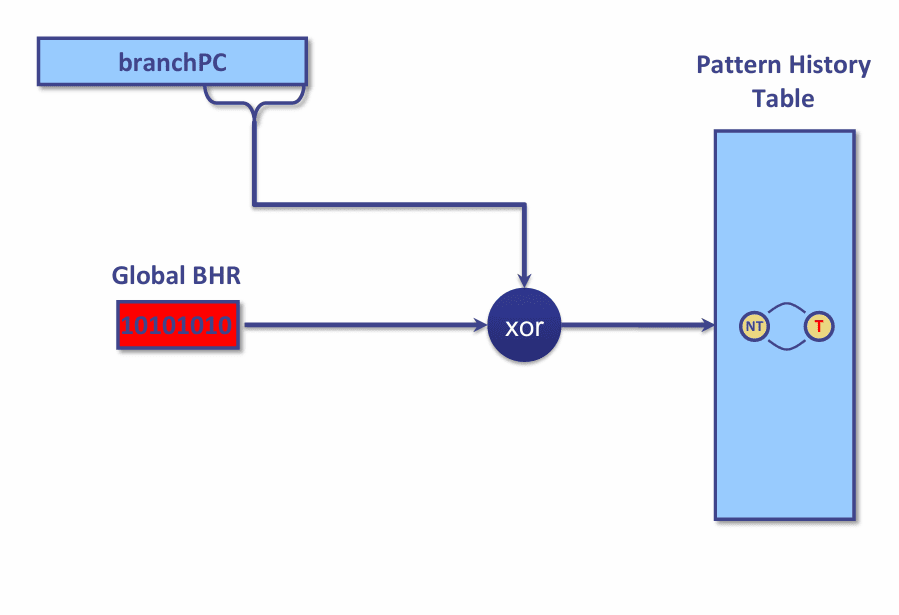
XOR 在这里的价值,远不只是“能混一下位”。它本身是一种很适合做索引混合的操作:输入稍微变一点,输出就可能明显变化,这能把原本集中在少数区域的访问打散,提升模式表的整体利用率。换句话说,GShare 不是简单把 PC 和历史拼在一起,而是尽量让不同分支、不同历史模式分散到更均匀的表项上,减少无谓的热点冲突。
这也是它长期流行的原因:快、便宜,而且效果好。当然,前提是模式历史表本身不能太小。表一小,原本被 XOR 打散的访问还是会重新撞在一起,别名冲突(aliasing)依旧严重。
随着工作负载越来越复杂,大家很快发现:没有一种单一预测器能把所有分支都处理好。
有些分支几乎与历史无关,用最简单的 bimodal 两位计数器就已经够准;有些分支则高度依赖相关性,不看历史就几乎猜不中。于是,混合预测器(hybrid predictor)出现了。它让一个简单预测器负责“历史无关”的分支,让一个相关预测器负责“真的需要历史”的分支,再由一个 chooser,也就是元预测器,决定当前这条分支该信谁。这样的组合非常有效,因为它承认不同分支本来就该用不同模型。实际效果也很明显:小容量的组合预测器,就能逼近远大于自身规模的单一预测器;而 local/gshare 这类组合在容量足够时,准确率还能继续向上走。
但组合并没有消灭另一个老问题:冲突干扰。多个分支映射到同一组表项时,常常会把计数器往相反方向推,造成负干扰。bi-mode predictor 针对这个问题,把模式表按 Taken 和 Not Taken 倾向分成两半,再由选择器决定当前应从哪一半取结果。这样做的好处是,天然偏向 Taken 的分支和天然偏向 Not Taken 的分支,不再那么容易挤在同一批表项里互相拉扯。
YAGS 则更进一步。它保留“主偏向”的判断,但不再把所有情况都塞进完整的 T/NT 两套大表里,而是只把“例外”缓存起来。也就是说,先假设一条分支通常遵循自己的主偏向,只有当它偶尔表现出反常行为时,才去命中特定的例外缓存。这种做法特别适合那种“总体很稳定,但少数情况下会反着来”的分支。
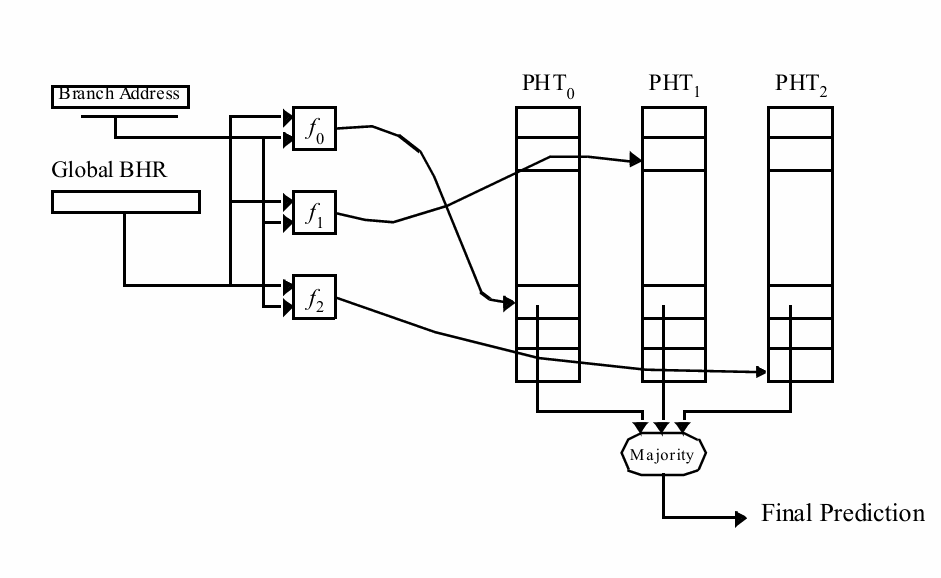
另一条路线是 gskewed predictor。它不试图让所有分支在一张表里和平共处,而是直接放多组模式表,并用不同的哈希函数分别索引。这样,两条本来会冲突的分支,不太可能在所有表里都同时撞上同一个位置。最后再通过多数投票给出结果。它的本质,是用“多视角映射”来对冲单一索引带来的冲突风险。
看到这里,现代分支预测的发展逻辑已经很明显了:一部分工作是在挖掘更深的相关性,另一部分工作则是在努力减少预测器内部的自相残杀。
到了 2000 年代初,像 2bcgskew 这样的设计已经相当强,但在一些工作负载上,开始显出对更复杂方法的疲态。真正把分支预测再次往前推了一大步的,是 TAGE。
TAGE 的关键想法很干脆:只围绕全局历史做文章,但同时准备多张带 tag 的表,每张表看不同长度的历史,而且这些历史长度按几何级数增长,比如 0、2、4、8、16、32,一路扩展到非常长。这样做的好处是,短历史表负责快速覆盖那些只依赖近邻行为的分支,长历史表则专门捕捉更深、更稀有的长期相关模式。
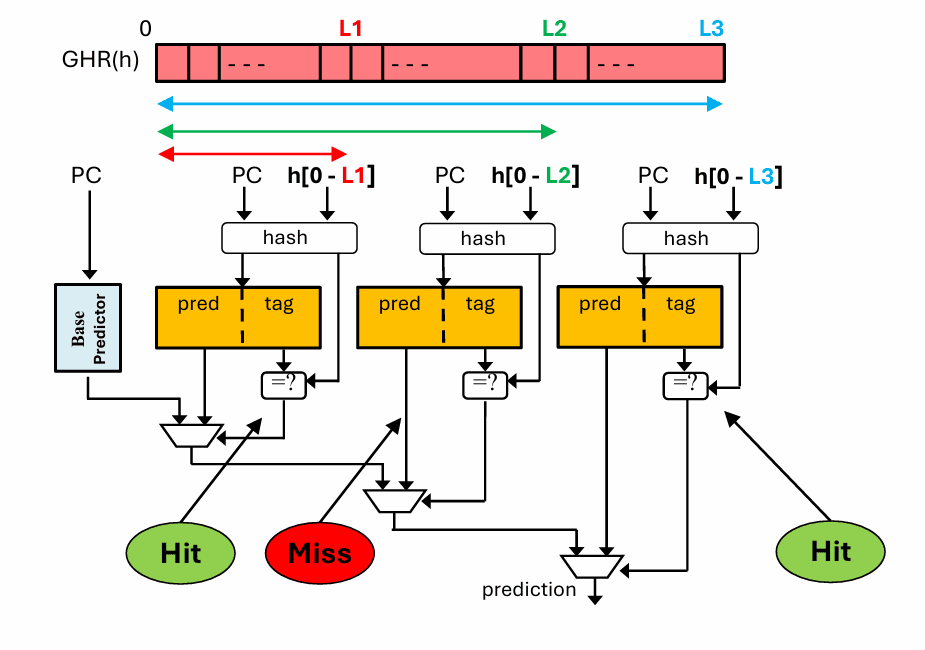
它之所以叫 TAGE,重点就在 tagged。表项里不只存一个预测值,还会带一部分 tag,用来确认“这次命中的到底是不是我想找的那类历史上下文”。这一步非常重要,因为历史一长,单靠索引命中很容易把不相关的模式误认为同一类。tag 的存在,相当于给长历史模式加了一层身份核验。
真正输出预测时,TAGE 通常选择“最长历史、且匹配成功、并且置信度足够”的那张表。如果更长历史的表没有命中,或者命中了但不够可靠,就退回到较短历史的表,最差还有基础预测器兜底。于是,TAGE 并不是在赌“最长历史一定最好”,而是在构建一个从短到长、从粗到细的层级系统:能用长历史时就吃掉复杂相关性,不能用时就稳定回退。
这正是它长期强势的原因。它同时解决了三个老问题:既保留了长历史的表达能力,又没有让所有分支都被迫承担长历史带来的训练成本,还通过 tag 显著减轻了别名冲突。也因此,TAGE 及其后续变体,直到今天仍然是高性能分支预测器中的核心代表。
分支预测一路演进下来,真正贯穿始终的并不是“表做得更大了”,而是三个更本质的目标:更好地利用相关性,更少地承受冲突,更谨慎地分配有限硬件资源。从两级相关预测器、GShare、混合预测器、bi-mode、YAGS、gskewed,一直到 TAGE,几乎每一步都在回答同一个问题:怎样才能在还没看到结果之前,用最小的代价做出最靠谱的判断。对现代处理器来说,这仍然是前端设计里最值得投入的一场“猜未来”工程。