Pie:面向新兴 LLM 应用的可编程服务系统
发布于 • 作者: In Gim et al.
本文是Pie: A Programmable Serving Systemfor Emerging LLM Applications的笔记与译文。





新兴的大语言模型(LLM)应用涉及多样化的推理策略和 代理式(agentic) 工作流,对基于单体化 token 生成循环构建的现有服务系统能力提出了挑战。本文提出 Pie,一种为灵活性与高效率而设计的可编程 LLM 服务系统。Pie 将传统的生成循环分解为细粒度的服务处理器,并通过 API 暴露,同时将生成过程的控制权交由用户提供的程序——称为 inferlet。这使得应用能够实现新的 KV cache 策略、定制化的生成逻辑,并将计算与 I/O 无缝集成——完全在应用内部完成,无需修改服务系统本身。Pie 使用 WebAssembly 执行 inferlet,从而受益于其轻量级的沙箱机制。评测结果表明,Pie 在标准任务上可达到当前最先进的性能(仅有 3–12% 的延迟开销),同时在代理式工作流上通过启用应用特定优化,显著提升了延迟与吞吐(1.3×–3.4× 的提升)。
CCS 概念:• 计算方法论 → 自然语言处理 关键词:LLM 服务、可编程推理、KV cache
ACM 参考格式: In Gim, Zhiyao Ma, Seung-seob Lee, and Lin Zhong. 2025. Pie: A Programmable Serving System for Emerging LLM Applications. In ACM SIGOPS 第 31 届操作系统原理研讨会(SOSP ’25),2025 年 10 月 13–16 日,韩国首尔。ACM,纽约,美国,16 页。https://doi.org/10.1145/3731569.3764814
大语言模型(LLM)的使用早已超越了简单的文本补全。如今的 LLM 服务系统需要复杂的策略来执行 LLM 应用逻辑,其范围从 token 级 到 工作流级。这些系统还必须处理实时用户事件,例如音频与视觉,并与外部工具和代码执行环境无缝集成,以支持日益常见的代理式工作流。
这些新兴的 LLM 应用暴露了当今服务基础设施在效率与灵活性方面的根本性局限(§2)。因此,我们提出了下一代 LLM 服务系统需要满足的三个需求:
R1. 应用特定的 KV cache 控制。 诸如 tree-of-thought 推理、map-reduce 摘要、多步生成等 LLM 工作流,需要对 KV cache 管理进行显式且细粒度的控制。这包括根据应用特定逻辑来定制分配、淘汰策略以及复用策略,而不是依赖服务系统内置的、隐式的全局启发式方法。
R2. 可定制的生成过程。 新兴的解码方法(如 assisted decoding、基于 MCTS 的生成)、有状态采样策略以及安全对齐,要求能够在按请求甚至按步骤的粒度上,精确控制并可能修改 token 预测与采样循环。
R3. 计算与 I/O 的一体化。 代理式工作流以及与外部系统的交互,需要在生成流程中将 token 生成与任意计算(例如运行符号检查)和 I/O 操作(例如进行 API 调用)紧密耦合,而不引入过高的延迟开销或复杂的外部编排。
现有系统(如 vLLM 和 TGI)由于依赖僵化的单体化 token 生成循环,难以满足上述需求(见图 1)。这种架构强制采用全局策略(例如 KV cache 管理,阻碍了 R1),使用封闭的生成过程而难以定制(阻碍了 R2),并将推理与外部操作(如工具使用)隔离开来,迫使客户端进行协调或要求对服务系统进行定制修改(阻碍了 R3)。尽管 SGLang 和 Parrot 等近期系统引入了一定的编程抽象,但它们在根本上仍受制于相同的单体化设计(§9)。
本文提出 Pie,一种旨在满足上述需求的可编程 LLM 服务系统。Pie 的核心思想是:将端到端生成过程的控制权交由用户提供的程序——inferlet。Pie 将生成过程分解为嵌入、前向计算、采样等阶段的细粒度处理器(见图 2),而不是采用全局的生成流水线。Inferlet 通过 API 调用来编排这些处理器(§4),从而显式管理诸如 KV cache 等资源、定义自定义生成逻辑,并直接集成任意计算与 I/O。
与将 prompt 视为基本服务单元不同,Pie 将程序提升为基本单元,使得数百个并发 inferlet 能够采用彼此不同的优化策略。例如,一个 inferlet 可以利用自定义 KV cache,另一个使用 speculative decoding,第三个则实现复杂的代理式循环,所有这些都运行在同一套底层服务基础设施之上(如图 2 所示)。从这一视角看,现有的服务系统本质上都运行着单一、固定的 inferlet,即自回归循环,这也解释了它们为何难以适应现代 AI 应用。
我们采用分层架构实现了 Pie(§5),并围绕 WebAssembly(Wasm) 构建 inferlet 运行时。开发者可以使用任何可编译为 Wasm 的编程语言(如 C++、Rust、Python),并通过 Pie 提供的 API 绑定来编写 inferlet。
我们的评估(§7)验证了 Pie 的有效性。我们将多种 LLM 技术实现为 inferlet,包括注意力变体、约束与推测解码、审慎提示策略以及代理式工作流。结果表明,Pie 在传统任务(如文本补全)上可匹配最先进系统的性能(延迟开销为 3–12%),同时在 Graph-of-Thought 和代理式工作流等高级任务上显著优于现有系统(1.1×–2.4× 更低的延迟,1.3×–3.4× 更高的吞吐),这得益于应用特定优化的支持。
本文的主要贡献如下:
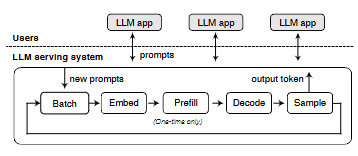 图 1:当前的 LLM 服务系统在概念上遵循单体化的 prefill–decode 循环,对 prompt 进行批处理并对 KV cache 应用全局策略。这种设计缺乏对应用特定逻辑的灵活支持。
图 1:当前的 LLM 服务系统在概念上遵循单体化的 prefill–decode 循环,对 prompt 进行批处理并对 KV cache 应用全局策略。这种设计缺乏对应用特定逻辑的灵活支持。
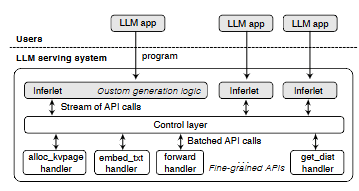 图 2:我们提出的系统 Pie 将顺序化的生成过程拆解为相互独立的处理器,并将控制权委托给用户提供的程序——inferlet。
图 2:我们提出的系统 Pie 将顺序化的生成过程拆解为相互独立的处理器,并将控制权委托给用户提供的程序——inferlet。
Pie 已在以下地址开源: https://github.com/pie-project/pie
我们首先概述现有 LLM 服务系统所依赖的体系结构,随后详细说明该架构在支持日益复杂的 LLM 应用时存在的不足。
现有的 LLM 服务系统被设计用于高吞吐量的文本补全,将每个用户请求视为一个单独的输入 prompt,并通过 prefill–decode 模型进行处理(见图 1)。该生成过程由若干离散步骤组成。首先是 prefill 阶段,系统并行处理整个 prompt,以填充初始的 Key-Value(KV)cache,从而避免重复计算。随后系统进入迭代式的 decode 阶段,在该阶段中,每一步都会利用 KV cache 和上一个 token 来预测并采样下一个 token,然后更新 cache。
为了最大化硬件利用率,一个中心化的调度器会将多个请求(prompt)组合成一个批次,并以 锁步(lockstep) 的方式推进它们完成每一个生成步骤。
当前的 LLM 服务架构围绕三个关键方面展开,而这些方面的内在僵化性给新兴应用带来了挑战:(1)KV cache 的管理方式,(2)token 预测与采样循环的固定结构,以及(3)生成过程与外部计算或工作流的集成方式。
当前系统通常通过隐式的、系统级的策略来管理 KV cache,例如 LRU 淘汰或 prompt caching,即在不同请求之间复用公共的前缀 token 序列。然而,这种方式无法为高级策略提供所需的应用特定控制能力。诸如 Recursion-of-Thought 和 Graph-of-Thought 等技术,要求在运行时根据应用的动态状态或推理结构,显式决定哪些 KV cache 块应被保留、丢弃、复用或复制——而这些决策是全局启发式策略无法胜任的。
此外,一些技术(如 attention sink 和 beam search)还需要对 KV cache 的结构进行细粒度操作。在单体化架构中实现这些功能,往往需要对系统内存管理器和调度器进行侵入式的深度修改。这种工程复杂性会阻碍功能的采用;例如,由于实现复杂性,vLLM(v0.6.3)曾考虑移除对 beam search 的支持。
在单体化循环中,“预测—采样” 操作被紧密耦合在一起,使得核心生成算法难以定制。新兴的解码方法(如 parallel decoding 或 speculative decoding)往往偏离标准流程,例如在每一步预测多个 token,或引入额外的验证步骤。由于这些方法的输出粒度是可变的,而常规流程假设每个请求在每个批处理步骤中只生成一个 token,因此将它们集成进来十分困难。
结果是,这类技术通常只能作为系统级开关来实现,而无法在按请求的粒度上灵活选择或配置。这种缺乏按请求定制的方式效率低下,因为不同应用,甚至同一应用的不同阶段,可能都适合采用不同的解码策略。类似地,MCTS 或 grammar-constrained decoding 等有状态生成策略需要跨步骤管理状态,而这在标准的无状态循环中实现起来十分笨重。最后,对输出分布进行动态控制(如用于水印或安全过滤)需要在采样步骤前后注入逻辑,而当前系统缺乏干净、可由应用定制的接口来实现这一点。
现有架构本质上假设生成过程是一个 “闭环” :系统仅基于初始 prompt 和模型内部状态来生成 token。这一假设并不适用于代理式工作流或交互式应用,这些应用需要将 token 生成与任意计算紧密集成,例如代码执行、API 调用或符号求解器。
在当前系统中,集成外部计算只能通过一种低效的变通方式实现:生成过程必须将控制权返回给客户端,由客户端执行外部操作,然后再提交一个新的请求并附带更新后的上下文以继续生成。这种往返会引入网络延迟。更为关键的是,由于服务系统在请求之间是无状态的,初始生成阶段的状态(即 KV cache)会被丢弃,系统会将后续生成视为一个新的 prompt,从而被迫对交互历史进行代价高昂的 re-prefill。虽然 prefix caching 等技术可以缓解这一问题,但它们仍然只是系统级启发式方法,而非对有状态交互的原生支持。
此外,在请求生命周期中引入应用特定的前处理或后处理步骤(例如自定义的 tokenization 调整)同样具有挑战性,除非引入过于复杂的 API。
综合来看,这些局限揭示了一种根本性的错配:为批量文本补全而优化的静态、单体化设计,无法高效或灵活地适应现代 LLM 应用所具有的动态性、异构性与交互性。其根本原因在于,应用控制逻辑与核心执行引擎在固定架构模式下被紧密耦合。要克服这些挑战,需要一种范式转变,即将应用的控制逻辑与底层模型执行基础设施解耦——而这正是 Pie 所体现的设计理念。
Pie 通过两项根本性的架构转变实现了可编程性,其核心洞见在于:只要提供合适的接口,应用特定的控制逻辑就可以高效地在核心推理引擎之外执行。
首先,Pie 将单体化的解码循环拆解为细粒度的过程。不同于固定的 prefill–decode 循环,Pie 暴露了一组彼此独立、粒度更细的服务(称为 handler),分别负责 token 预测流程中的特定阶段,例如输入文本嵌入、KV cache 操作(如分配与更新)以及模型前向计算。其次,Pie 将端到端的控制权委托给用户提供的程序,称为 inferlet。这些 inferlet 通过向 handler 发出 API 调用来定义定制化的生成工作流。Inferlet 可以:
为实现这一可编程模型,Pie 采用了一种兼顾灵活性与效率的分层架构。从整体上看,用户的 inferlet 在专用的应用层中执行,并通过 API 与系统交互。控制层负责协调这些交互,进行资源管理、访问虚拟化,并对发往硬件的 API 调用进行智能批处理。最后,推理层执行这些批处理操作,并通过针对不同模型算子的专用 handler,将其转化为底层计算(例如 GPU kernel 调用)。
接下来的章节将详细介绍该设计。第 4 节介绍 Pie 的编程模型,说明 inferlet 用于编排生成与管理资源的 API 原语。第 5 节阐述三层系统架构,并解释其如何支持 inferlet 的执行、管理控制流,以及与底层推理硬件进行交互。
Pie 的编程模型为开发者提供了一组 API,用于创建所谓的 inferlet——用于编排 LLM 生成的专用程序。每个 inferlet 都在一个单线程、事件驱动的运行时中执行。Inferlet 内部的并发通过异步、非阻塞的 API 调用来实现,这种模型非常适合 I/O 密集型的代理式工作流,因为此类工作流往往需要长时间等待 API 调用或工具执行完成。
Inferlet 的编程模型围绕三个关键目标设计:(1)表达能力——支持广泛的生成逻辑,尤其是满足 §1 中提出的 R1–R3;(2)效率——通过细粒度的资源控制实现性能优化;(3)可扩展性——对具体的 LLM 架构保持无关性,同时为未来扩展提供基础。
表 1 给出了 Pie API 的整体概览。在总计 42 个 API 中,有 18 个是定义 LLM 前向计算与推理层资源管理的核心 API,我们将在 §4.1 中详细说明。其余 24 个 API 用于运行时管理、inferlet 之间的通信以及 I/O,这些能力对于构建交互式、代理式应用至关重要。这部分 API 不需要 GPU 参与,完全由控制层处理,我们将在 §4.3 中介绍。
作用范围与权衡。 Pie API 面向基于 Transformer 的 LLM 设计。它将整体工作流抽象为三个阶段,并通过 API 将每个阶段暴露为一个不透明的函数。因此,诸如 kernel 融合与调度、量化技术或张量并行执行策略等底层 GPU 优化,仍然是正交问题,由推理层负责处理(§5)。Pie API 优先考虑细粒度的可编程性而非简洁性,这不可避免地带来了编程复杂度。为此,我们提供了一个高层支持库,其中包含常用的子例程与抽象,以减轻开发负担(§6.3)。
Pie 将 LLM 的前向计算视为一个三阶段过程:(1)embed,从原始数据(文本、图像)中准备输入嵌入;(2)forward,从输入嵌入计算输出嵌入,并可选择性地利用 KV cache;(3)sample,从输出嵌入中派生有意义的输出(例如下一个 token 的 logits)。与模型前向计算相关的 API 均属于这三个类别之一。Inferlet 通过组合来自不同阶段的 API 调用来定义一个完整的前向计算流程。
资源。 Pie 定义了两类主要资源,并允许它们以指针形式在不同阶段之间传递。(1)Embed 表示一序列 token 嵌入(输入或输出),以 per-token 的方式分配,从而提供对单个 token 表示进行灵活操作的能力。(2)KvPage 表示 KV cache 的一个连续块,遵循 PagedAttention 的设计。一个 KvPage 可包含 8–32 个 token。Pie 要求 inferlet 显式地进行资源分配与释放(例如表 1 中的 alloc_embed 和 alloc_kvpage)。返回的资源句柄是指向 Pie 所管理底层内存的不透明指针。每个 inferlet 都拥有独立的虚拟资源地址空间,由 Pie 的控制层管理。通过 import/export API(见表 1),资源也可以在 inferlet 之间共享,控制层会负责必要的物理—虚拟地址映射。
命令队列。 Command queue 抽象了一条 inferlet 发出的 API 调用的逻辑序列,其目的是帮助批处理调度器(§5.2)做出最优的批处理决策:(1)明确 API 调用之间的依赖关系;(2)允许在不同队列之间设置优先级。所有需要由批处理调度器处理的 API 调用(如资源分配/释放、前向计算和采样)都需要将一个命令队列对象(Queue)指针作为参数。相对地,不需要批处理的 API(如 I/O 操作)则不需要命令队列参数,而是直接由控制层处理。
例如,在下面的 inferlet 程序中,Pie 的控制层可以根据不同的 Queue,对两个 forward API 调用进行批处理,从而使 GPU 能够在推理层中并行处理它们:
q1, q2 = create_queue(), create_queue()
forward(q1, [], iemb1, [], oemb1)
forward(q2, [], iemb2, [], oemb2)
await synchronize(q1)
await synchronize(q2)
Embed API 负责将原始输入数据(例如文本、图像)转换为 Embed 指针,供其他 API 使用。该类别中的关键函数包括 embed_txt 和 embed_img,它们会根据提供的输入数据填充已分配的 Embed 指针。此外,Pie 还提供了 tokenize、detokenize 以及 num_embeds_needed 等辅助函数,用于支持该阶段中的预处理与嵌入相关操作。
forward 与 forward_with_adapter 属于此类别。forward API 执行 Transformer 的前向计算;forward_with_adapter 允许用户指定 LoRA adapter,以支持微调模型。
forward API 接收输入 Embed 和/或输入 KvPage,执行注意力与变换计算,并生成输出 Embed 和/或输出 KvPage。forward 基于与资源显式关联的序列位置进行操作。该 API 可以接收显式的布尔矩阵形式的注意力掩码,或者根据提供的序列位置自动推断。例如,若省略位于输入 Embed 之前的某个 token 的 KvPage,则该 token 在注意力计算中会被有效屏蔽。这使 inferlet 能够直接操纵注意力上下文,这对于依赖自定义注意力掩码或模块化缓存的技术至关重要。
我们在下面的代码中展示了其用法。第 1–3 行在给定 9 个 token 的情况下生成一个输出嵌入(即 prefill)。同样的操作也可以拆分为两次 forward 调用,如第 6–7 行所示,其中使用一个 KvPage 来存储中间状态。需要注意的是,第 6–7 行中的 forward API 调用可能会被合并批处理,尽管它们使用的是同一个命令队列,这一点将在 §5.2 中关于纵向批处理的部分进一步说明。
iemb = alloc_emb(9) # 9 个输入 token
oemb = alloc_emb(1) # 1 个输出 token
forward([], iemb, [], oemb)
# 在示例中,1 个 KvPage = 1 个 token
kv = alloc_kvpage(8) # 8 个 token
forward([], iemb[:-1], kv) # 生成 kvpage
forward(kv, iemb[-1:], oemb) # 使用 kvpage
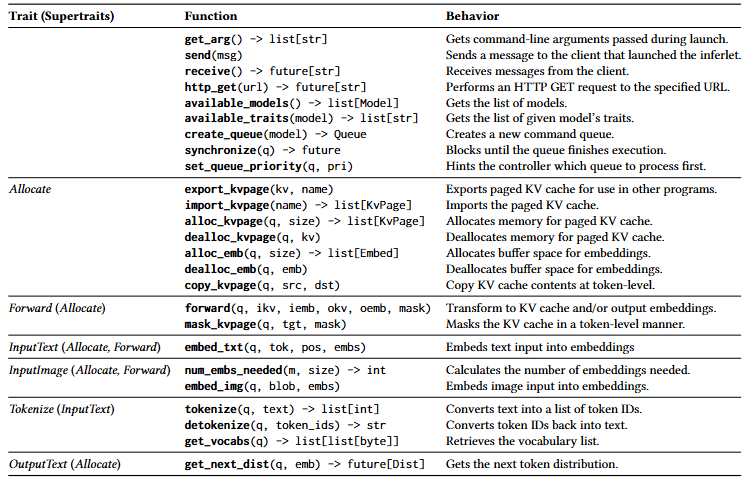 表 1:用于编写 inferlet 的 API 概览(非穷尽)。Pie 共提供 42 个 API,其中 18 个用于 LLM 执行,其余 API 用于支持核心运行时操作与代理式工作流。为确保模型无关性与可扩展性,Pie 将 LLM 相关 API 组织为 trait(§4.4)。涉及命令队列(
表 1:用于编写 inferlet 的 API 概览(非穷尽)。Pie 共提供 42 个 API,其中 18 个用于 LLM 执行,其余 API 用于支持核心运行时操作与代理式工作流。为确保模型无关性与可扩展性,Pie 将 LLM 相关 API 组织为 trait(§4.4)。涉及命令队列(q)的 API 调用由推理层处理,不涉及命令队列的调用则直接由控制层处理。
Pie 提供了一组 API,用于从 forward API 生成的输出嵌入中提取最终结果。例如,get_next_dist 接收一个 Embed 作为输入,并输出下一个 token 的概率分布。随后,inferlet 可以使用宿主语言自行控制采样或其他后处理逻辑。这种灵活性对于实现自定义采样策略以及基于概率的 LLM 内省(如 LLM watermarking)非常有用,因为这些方法需要广泛访问底层的 token 分布。
将完整的分布返回给 inferlet 在词表规模较大时(例如 Llama 3 的 128K 词表)可能会带来显著的内存开销。为缓解这一问题,Pie 会将分布截断为 Top-K token。K 由用户配置,默认值为 256。
上述原语为实现自定义生成逻辑提供了基础构件。下面我们实现一个自回归循环:给定输入提示词 “Hello,”,使用贪心采样生成 10 个新 token。由于该示例中只使用了一个命令队列,为简洁起见省略了 Queue 参数。
prom = tokenize("Hello,")
tok_limit = len(inp) + 10
# 资源分配
prom_emb = alloc_emb(len(prom))
gen_emb = alloc_emb(1)
kv = alloc_kvpage(tok_limit)
# Prefill
pos = list(range(len(prom)))
embed_txt(prom, pos, prom_emb)
forward([], prom_emb, kv[:len(prom)], gen_emb)
# Decode
for i in range(len(prom), tok_limit):
dist = await get_next_dist(gen_emb)
gen = dist.max_index()
print(detokenize(gen))
embed_txt(gen, [i], gen_emb)
forward(kv[:i], gen_emb, kv[i:i+1], gen_emb)
# 资源清理
dealloc_emb(prom_emb)
dealloc_emb(gen_emb)
dealloc_kvpage(kv)
inferlet 的编程模型提供了类似 OpenGL 在 GPU 图形编程中所具备的细粒度控制能力。需要底层灵活性的开发者可以直接编排资源与生成逻辑,而大多数用户则可以依赖构建在该基础之上的高层抽象或可复用库。在实践中,许多应用只需使用这些库,或直接运行满足需求的预编译 inferlet。例如,Pie 的支持库(§6.3)允许用户仅用三行代码就实现上述自回归循环:
ctx = Context(model)
ctx.fill("Hello,")
ctx.generate_until(max_tokens=10)
Pie 提供了一组关键的运行时 API,例如用于读取命令行参数的 get_arg、查询可用模型的 available_models,以及支持用户(即发起 inferlet 的客户端)与 inferlet 之间通信的 send、receive。此外,inferlet 还可以独立执行 I/O 操作,例如通过网络 API(http_get、http_post)与外部服务器交互,或通过消息传递 API(broadcast、subscribe)与其他 inferlet 协作。这些能力使得能够构建动态、交互式的工作流,将 LLM 推理与外部数据、工具、计算以及其他代理无缝集成。
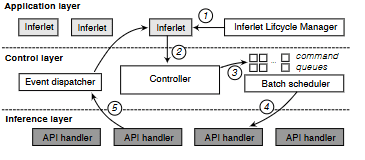 图 3:Inferlet 的服务工作流(§5)。应用层执行 inferlet,并向控制层发出 API 调用;控制层中的批处理调度器会自适应地对这些调用进行批处理,并将其转发至推理层。结果随后返回控制层,并最终返回给 inferlet。
图 3:Inferlet 的服务工作流(§5)。应用层执行 inferlet,并向控制层发出 API 调用;控制层中的批处理调度器会自适应地对这些调用进行批处理,并将其转发至推理层。结果随后返回控制层,并最终返回给 inferlet。
LLM 在能力上存在差异(例如仅支持文本或支持多模态),并且可能会随着时间推移获得新的功能。为了提供稳定且可扩展的 API,Pie 将每一组相关操作定义为一个 Trait(类似于 Rust 中的 trait)。例如,InputText trait 包含 tokenize 和 embed_txt,而 Forward trait 则包含 forward。具体的模型实现可以实现一个或多个 trait,而 trait 之间也可以存在依赖关系(即 supertrait)。表 1 总结了当前已定义的 trait。要支持新的模态(例如音频输入)或新能力,只需定义一个新的 trait,并让模型实现该 trait 即可。基于旧 trait 编写的 inferlet 无需修改即可继续工作。
Inferlet 可以在运行时通过 available_traits 查询模型所支持的 trait,并据此动态调整其逻辑。另一方面,trait 还可用于扩展 API 集合,以支持当前 API 无法实现的高级优化。例如,PyramidKV 和 AdaKV 等方案依赖于模型内部统计信息(如 token 级注意力分数)。可以定义 Forward trait 的一个变体(例如 IntrospectiveForward),返回这些统计信息,从而使 inferlet 能够实现自定义缓存策略。
Pie 采用如图 3 所示的三层架构——应用层、控制层与推理层——以高效地为多个用户 inferlet 提供服务。该设计实现了关注点分离:应用层管理单个 inferlet 的生命周期;控制层负责系统范围内的资源协调,包括 API 调用的批处理调度;推理层则处理模型推理任务在 GPU 上的底层执行。
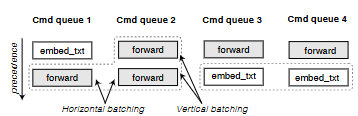 图 4:批处理调度示例(§5.2)。来自命令队列 3 和 4 的两个
图 4:批处理调度示例(§5.2)。来自命令队列 3 和 4 的两个 embed_txt API 调用,或来自队列 1 和 2 的三个 forward API 调用,都可以被组成批次并发送至推理层。横向批处理在不同命令队列之间组合调用,而纵向批处理则在同一队列内组合不发生冲突的、连续的同类型调用。
应用层在一个为 inferlet 提供隔离的运行时中执行 inferlet。Pie 使用 WebAssembly(Wasm) 运行时来执行并沙箱化 inferlet,并作为 inferlet 通过 §4 所述 API 与 Pie 交互的接口。应用层中的 Inferlet Lifecycle Manager(ILM) 负责 inferlet 的生命周期管理,包括创建、销毁以及通信。ILM 提供 RPC 接口,用于查询、提交以及使用 Wasm 二进制文件和参数来启动 inferlet(见图 3 中的 ①)。inferlet 启动后,用户可以通过 ILM 与其通信,而 inferlet 内部则通过 send 和 receive API 处理这些用户事件。
控制层通过对 Pie API 调用进行批处理并将其路由到推理层操作,连接了应用层与推理层,同时提供资源抽象。一个中央控制器处理来自大量并发 inferlet 的 API 调用(见图 3 中的 ②),并执行三项关键功能:(1)直接处理不需要 GPU 的 API 调用(例如核心运行时 API 和 I/O);(2)管理 Embed 与 KvPage 资源的分配与虚拟地址映射(§4.1);(3)使用批处理调度器对 GPU API 调用(如 forward、embed)进行分组,以提升性能(③)。事件分发器接收来自推理层的结果,并将其广播回 inferlet(⑤)。
资源管理。 控制层管理一个全局的 Embed 与 KvPage 资源池,这些资源在物理上位于推理层,其大小在启动时根据 GPU 内存进行配置。控制层通过分配 API(如 allocate_kvpage)为 inferlet 提供这些资源的虚拟化视图,以实现 inferlet 之间的资源隔离。当发生资源争用时,控制层采用 先来先服务(FCFS) 策略,通过终止最近创建的 inferlet 来释放足够的资源。
批处理调度器。 为了提升 GPU 利用率与整体吞吐量,批处理调度器会在将 GPU 相关的 API 调用发送到推理层之前,对其进行分组。如图 4 所示,调度器按命令队列(§4.1)管理待处理的 API 调用,并利用命令队列所提供的明确依赖关系与优先级,通过两种技术构建批次:
在一个批次内部,来自高优先级队列的调用会被放置在更靠前的位置。如果某个批次超过了推理后端所支持的最大规模,调度器会从尾部进行截断。当存在多种 API 类型的候选批次时,调度器会选择等待时间最长的最早调用所在的批次。一个核心挑战在于决定何时调度:过早调度会导致 kernel 利用不足,而等待过久则会增加延迟。Pie 采用一种工作保持(work-conserving)策略(§6.1)来最大化 GPU 利用率。
推理层是 Pie 的硬件执行后端。它通过 RPC 接收来自控制层的批处理 API 调用,并管理物理上的 Embed 与 KvPage 资源,这些资源根据控制层在启动时设定的配置进行分配。需要强调的是,资源管理完全由控制层负责,而推理层仅持有实际内存。
推理层包含多个 API handler,每个 handler 专门执行一种需要 GPU 参与的批处理 API 调用(例如 forward)。在接收到一个批次后(见图 3 中的 ④),handler 会通过调用必要的 GPU 侧张量操作来完成 API 请求,并将结果发送回控制层的事件分发器(⑤)。
推理层运行在与硬件加速器相连的宿主服务器上,并通过 进程间通信(IPC) 与控制层进行交互。
Pie 的实现共包含 13,650 行源代码(通过 cloc 统计),其中 11,640 行用于用 Rust 编写的核心系统与支持库,其余代码用于用 Python 实现的 GPU 侧 API handler。Pie 使用 wasmtime 作为 Wasm 运行时来执行 inferlet,并通过 WASI 提供诸如网络 I/O 等系统接口。当前的 API handler 支持 Llama 系列模型。我们重点介绍两个能够提升系统性能的实现要点,并进一步描述一个通过提供高层抽象来简化开发的支持库,用于实现常见的生成模式。
我们采用一种简单的工作保持策略来实现批处理调度器(§5.2)。GPU 可以处于两种状态之一:忙碌或空闲。当 GPU 处于忙碌状态,即正在处理某些 API 调用时,调度器会将新到达的 API 调用排队。一旦 GPU 变为空闲状态,推理层会立即通过 IPC 通知控制层,以触发批次的构建。
我们使用 PyTorch 和 FlashInfer GPU kernel 库来实现推理层的 API 处理器。这些处理器通过 ZeroMQ 与控制层通信,ZeroMQ 是一个支持 IPC 的消息传递库。作为开源发布的一部分,我们还提供了一个原生 C++/CUDA 的推理层实现,该实现不依赖 PyTorch。在我们的测量中,与 Python/PyTorch 版本相比,它实现了 10–30% 更低的端到端延迟以及更高效的 GPU 内存利用率,这得益于其自定义的内存管理机制,该机制会预分配并复用 GPU buffer,从而避免内存碎片化。由于该实现目前仅支持部分 API trait(例如 Forward、InputText),因此我们在此未进行完整评估。感兴趣的读者可在项目主页中找到更多细节。
我们提供了一个用 Rust 编写的支持库,以简化 inferlet 的开发。该库提供了过程宏和一个轻量级异步运行时,用于减少定义 Wasm 入口点所需的样板代码,并支持在 inferlet 中直接使用 async/await 语法。我们还提供了高层抽象,例如用于自动管理 KvPage 的 Context,并实现了常用的子例程,如采样方法(例如 top-k、temperature)、停止条件(例如 end-of-sequence 或最大 token 数),以及类似 SGLang API 的 fork-join 并行机制,从而减少在每个 inferlet 中重复实现这些功能的需求。
在评估中,我们重点回答以下问题:
Q1. Pie 的编程模型(§4)如何在满足 §1 中 R1–R3 要求的同时,促进新兴 LLM 应用的部署?(§7.1–§7.2) Q2. 与现有 LLM 服务系统相比,Pie 是否能够有效降低端到端延迟并提升吞吐量?(§7.3) Q3. Pie 的可编程 LLM 服务系统设计引入了哪些开销?(§7.4)
实验设置。 在评估中,我们使用了一台 GCP VM G2 实例(g2-standard-32),配备一张具有 24 GB 显存的 NVIDIA L4 GPU,用于部署 Pie 及其基线系统。我们使用 Llama 3 模型(1B、3B、8B),权重采用 BF16 精度;KV cache 和激活同样使用 BF16。端到端延迟的测量来自校园网络中的远程 Python 客户端,其连接到运行在 GCP 实例上的服务系统。
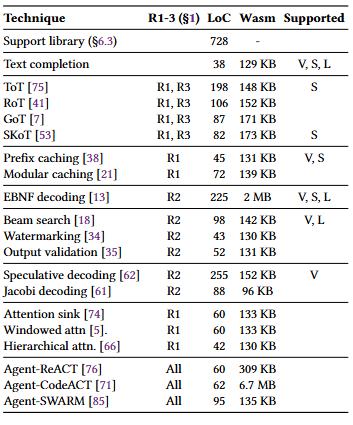 表 2:以 inferlet 形式实现的 LLM 应用与推理技术,以及对应的代码行数(LoC)和编译后的 Wasm 二进制大小。右侧列出了 vLLM(V)、SGLang(S)和 LMQL(L)的支持情况。Wasm 二进制大小可通过去除调试符号进一步减小。部分应用(如 CodeACT)由于嵌入了诸如 JavaScript 运行时等库,因此二进制体积较大。
表 2:以 inferlet 形式实现的 LLM 应用与推理技术,以及对应的代码行数(LoC)和编译后的 Wasm 二进制大小。右侧列出了 vLLM(V)、SGLang(S)和 LMQL(L)的支持情况。Wasm 二进制大小可通过去除调试符号进一步减小。部分应用(如 CodeACT)由于嵌入了诸如 JavaScript 运行时等库,因此二进制体积较大。
基线系统。 我们将 Pie 与当前最先进的 LLM 服务系统进行比较,包括 vLLM(v0.6.0)、SGLang(v0.4.4),以及在相关场景下的专用框架,如用于结构化生成的 LMQL 和用于 attention sink 的 StreamingLLM。为确保比较聚焦于架构差异而非 kernel 优化,Pie、vLLM 和 SGLang 均使用 FlashInfer GPU 后端。
应用场景。 为展示 Pie 的表达能力与性能(Q1、Q2),我们使用 Pie API 和 Rust 实现了多种 LLM 应用,详见表 2。这些应用涵盖了标准技术、高级推理策略以及代理式工作流。在基线对比中,我们使用 Python 脚本通过各系统的 API server 复现相同的高层应用逻辑。
代理式工作流将 LLM 推理与外部工具或多步推理相结合,凸显了计算与 I/O 无缝集成的重要性。我们将三种具有代表性的代理——ReACT(Web API 交互)、CodeACT(代码执行)和 Swarm(代理间通信)——实现为 inferlet,以展示 Pie 对 I/O 共置的支持。作为对比,我们在 vLLM 和 SGLang 中使用 Python 脚本复现相同的工作流,并在有利于吞吐量的情况下尽力进行优化和客户端请求并行化。
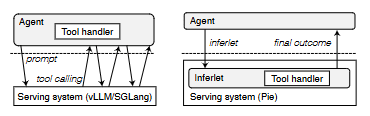 图 5:在 vLLM/SGLang(左)与 Pie(右)中实现代理式工作流的对比。
图 5:在 vLLM/SGLang(左)与 Pie(右)中实现代理式工作流的对比。
Pie 与基线系统在实现上的主要差异如图 5 所示。在基线系统中,应用逻辑完全位于客户端,而服务系统仅负责 LLM 推理。这种分离会导致每次外部交互都产生往返延迟,并在上下文发生变化时可能触发 re-prefill。相比之下,Pie 的 inferlet 在同一运行时中封装了推理与外部交互,消除了这些往返开销,并允许直接操作 KV cache,以在多次交互之间保留上下文。
我们在图 6 中测量了延迟与吞吐量,使用的是 1B 模型,并分别在每个代理中包含 8 次(ReACT)、8 次(CodeACT)和 32 次(Swarm)外部 I/O。测得的延迟分别为 4.27 s、3.18 s 和 6.14 s,对应的吞吐量分别为 29.94、40.18 和 5.21 agents/s。Pie 显著优于基线系统,例如在 ReACT 上延迟最多降低 15%,吞吐量最多提升 30%。性能提升与工作流中 I/O 与 token 总数的比例密切相关。例如,当外部交互次数少于两次时,我们未观察到基线系统之间的性能差异;而随着交互次数增加,差距呈线性扩大。
性能提升主要来自两个因素。对于较小模型(1B、3B),主要因素是消除了客户端与服务器之间的往返延迟,因为往返时间(数十毫秒)与 token 生成时间(数毫秒)处于同一量级。对于较大模型(8B 及以上),主导因素则是能够在外部交互之间保留 KV cache,从而避免基线系统所需的高成本 re-prefill。
新的 LLM 生成策略可以提升推理能力、输出质量和效率,但往往需要修改底层服务系统才能高效实现,甚至在现有系统中难以实现。Pie 的可编程性解决了这一挑战,使用户能够在无需修改核心系统的情况下,将新策略实现并部署为 inferlet。
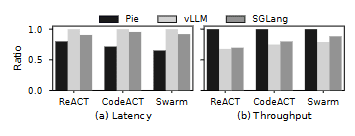 图 6:不同服务系统(Pie、vLLM、SGLang)托管的 LLM 代理的延迟(越低越好)与吞吐量(越高越好)。横轴为 ReACT、CodeACT 和 Swarm。数值在每种情况下均归一化到最长延迟或最高吞吐量。
图 6:不同服务系统(Pie、vLLM、SGLang)托管的 LLM 代理的延迟(越低越好)与吞吐量(越高越好)。横轴为 ReACT、CodeACT 和 Swarm。数值在每种情况下均归一化到最长延迟或最高吞吐量。
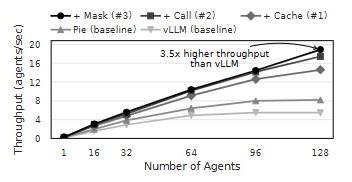 图 7:通过对简单代理式工作流应用工作负载特定优化所获得的性能提升(§7.2)。多种优化叠加可进一步提升性能。
图 7:通过对简单代理式工作流应用工作负载特定优化所获得的性能提升(§7.2)。多种优化叠加可进一步提升性能。
Pie 为应用层推理优化创造了新的机会。考虑一种典型的代理式工作流:根据用户查询以及提供的可用 API 集合,触发多次 LLM 函数调用以访问外部 API。假设该应用具有以下独特特性:
这些应用特定知识无法被现有服务系统显式利用;现有系统通常依赖诸如 vLLM 中的自动前缀缓存等隐式优化。然而,Pie 用户可以通过以下技术对该工作流进行优化,每一种技术分别利用了上述某一特性:
export_kvpage 保留高频使用 API 文档对应的 KV cache。mask_kvpage 从上下文中丢弃仅使用一次的 API 规范对应的 KV cache。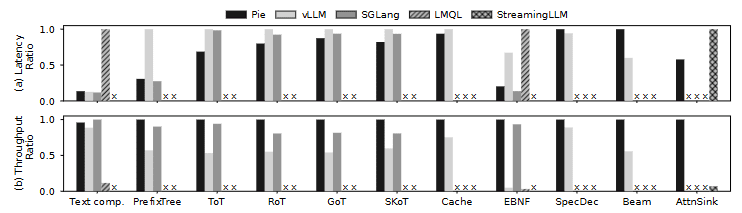 图 8:不同服务系统托管的示例 LLM 推理技术的延迟(越低越好)与吞吐量(越高越好)。数值的归一化方式与图 6 相同。Pie 在性能上与最先进的服务系统相当。× 表示不支持的技术或无法进行的比较。例如,SGLang 不支持 Pie 和 vLLM 所使用的特定推测解码实现。
图 8:不同服务系统托管的示例 LLM 推理技术的延迟(越低越好)与吞吐量(越高越好)。数值的归一化方式与图 6 相同。Pie 在性能上与最先进的服务系统相当。× 表示不支持的技术或无法进行的比较。例如,SGLang 不支持 Pie 和 vLLM 所使用的特定推测解码实现。
如图 7 所示,每一次连续的优化都会在前一次的基础上叠加效果,最终相较于在 vLLM 上以 Python 实现的基线工作流,实现了 3.5× 的吞吐量提升。这表明,Pie 对 KV cache 的细粒度控制(R1)、对生成过程的控制(R2)以及对 I/O 的控制(R3),使开发者能够根据应用语义量身定制推理策略,从而获得远超通用系统特性(如前缀缓存)所能提供的显著性能收益。
我们将四种审慎提示策略实现为 inferlet:Tree-of-Thought(ToT)、Recursion-of-Thought(RoT)、Graph-of-Thought(GoT) 以及 Skeleton-of-Thought(SkoT),每种实现大约包含 80–100 行代码(见表 2)。在实现中,我们使用了原论文中任务的简化版本(例如,ToT 与 RoT 使用算术任务,GoT 使用文档摘要任务)。对于 RoT,我们允许递归分支的最大深度为 5,从而最多产生 $2^5 = 32$ 个分支。
在这四种策略上,Pie 均实现了更优的性能,相较基线系统延迟最多降低 28%,吞吐量最多提升 34%。性能优势源于 Pie 由程序控制的 KV cache 复用机制,其控制粒度和灵活性均优于现有系统中的隐式 KV cache 管理。这一点对于 Recursion-of-Thought 等复杂策略尤为有利,因为在图结构高度动态的情况下,SGLang 的 RadixAttention 无法有效应用。此外,Pie 的集成式 I/O 能力也为 Tree-of-Thought 等策略带来了额外性能收益,使系统能够在价值评估阶段(例如用于裁剪搜索空间的符号求值)高效地交错执行计算。
借助 mask_kvpages 以及 forward API 中的 mask 参数,Pie 可以实现多种注意力级技术,包括 attention sink、windowed attention 和 hierarchical attention。据我们所知,这些技术此前尚未在 vLLM 或 SGLang 中实现。因此,我们将 Pie 与专用实现进行对比,例如用于 attention sink 的 StreamingLLM。与原始 StreamingLLM 实现相比,Pie 展现出显著的性能提升,实现了 1.5× 更低的延迟以及 30× 以上的吞吐量提升。尽管该对比结果会受到底层 GPU kernel 库差异的影响,但它凸显了 Pie 将注意力级技术以 inferlet 形式高效表达与实现的能力。
Pie 的一个关键特性在于,它能够以编程方式复现其他 LLM 服务系统中通常作为单体、系统级特性实现的优化。这使得这些优化可以被组合使用,并按应用需求进行定制。我们将多种此类特性实现为 inferlet。
对于前缀缓存,我们使用 export_kvpage 与 import_kvpage 复现了 vLLM 的机制,以实现由应用控制的缓存共享。对于推测解码,我们实现了 vLLM 的 n-gram prompt-lookup 方法。我们还实现了 beam search。此外,我们通过管理共享的 KV 前缀与分支流,构建了前缀树(等价于 RadixAttention),以支持 SGLang 风格的分支生成。最后,我们通过 Wasm 集成了一个基于 Rust 的约束解码库 llguidance,在每一步对 token 采样进行约束,从而实现结构化生成。其中,EBNF 实现展示了 Pie 无缝集成第三方库的能力。
如图 8 所示,Pie 在这些任务上的性能总体上与 vLLM 和 SGLang 相当。在使用三个 beam 的 beam search 中,Pie 的延迟略高,但吞吐量更优。在使用 JSON 语法的 EBNF 解码中,Pie 的性能与 SGLang 持平,并显著优于 vLLM 和 LMQL。这些结果表明,Pie 的编程模型在表达能力与效率方面兼具优势,能够在应用层实现最先进的优化。
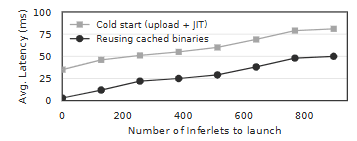 图 9:启动一个 inferlet 的平均延迟。与逐 token 生成延迟相比,该延迟可以忽略不计。对 JIT 编译后的二进制进行缓存有助于进一步降低启动延迟。
图 9:启动一个 inferlet 的平均延迟。与逐 token 生成延迟相比,该延迟可以忽略不计。对 JIT 编译后的二进制进行缓存有助于进一步降低启动延迟。
我们通过一系列微基准测试来分析 Pie 的编程模型与系统架构所引入的性能影响与开销。
Pie 被设计为同时服务多个并发的 inferlet,每个 inferlet 都运行在独立的 Wasm 运行时实例中,并发数量可扩展至数百个。这可能引发对大量 inferlet 启动开销的担忧。为此,我们测量了用于文本补全任务(见表 2)的 inferlet 启动端到端时间。具体而言,我们修改了 text_completion inferlet,使其在开始 token 生成之前先向用户发送一条确认消息。随后,从 Python 客户端测量从发起 inferlet 启动请求到接收到确认消息之间的时间。
我们在两种场景下测量该延迟:冷启动与热启动。在冷启动中,客户端在启动 inferlet 前上传 Wasm 二进制文件,Pie 对接收到的二进制进行 JIT 编译;在热启动中,客户端直接使用 Pie 中缓存的二进制文件。如图 9 所示,当多达 896 个 inferlet 同时请求启动时,热启动的开销为 10–50 ms,冷启动为 35–81 ms。鉴于典型的逐 token 生成延迟为 10–60 ms,这一启动开销可以忽略不计。Pie 能够实现如此低的启动延迟,得益于 wasmtime 的 pooled allocation 特性,它为最多 1,000 个并发实例预分配了 Wasm 运行时所需的虚拟内存。
由于 inferlet 在一次任务中可能触发数百到数千次 API 调用,这可能成为性能瓶颈,因此我们分析了 API 调用的开销。API 调用分为两类:(1)由控制层处理的调用(如 get_arg、send);(2)由推理层处理的调用(如 forward、embed_txt)。图 11 展示了不同任务中 API 调用的频率,并按生成的输出 token 数进行了归一化。
对于基础文本补全任务,每生成一个输出 token,大约对应 1.6 次由推理层处理的调用和 1.5 次由控制层处理的调用。而在更复杂的操作(如 beam search,宽度为 3)中,每生成一个 token 分别对应约 17 次和 13 次由推理层与控制层处理的调用。我们以微秒级测量每次 API 调用的开销,如图 10 所示。该开销定义为从发出 API 调用到其完成的时间,不包含实际处理时间(例如 GPU 执行或控制器处理,8B 模型下通常为 6–50 ms/ token)。在该测量中,我们禁用了批处理调度。由于大多数 API 调用是异步执行的,部分延迟可以被隐藏,因此测得的值代表上界。
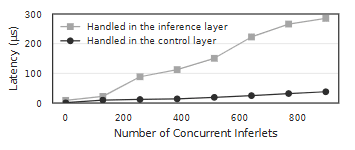 图 10:由控制层或推理层处理的 API 调用延迟。推理层更高的延迟主要来自 IPC 边界跨越以及 Python 侧 API 调用反序列化的开销。
图 10:由控制层或推理层处理的 API 调用延迟。推理层更高的延迟主要来自 IPC 边界跨越以及 Python 侧 API 调用反序列化的开销。
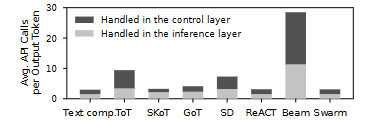 图 11:按生成 token 数归一化后的任务平均 API 调用次数。Beam search(beam=5)涉及显著更多的 API 调用,因为只有获胜 beam 的 token 被计为输出。
图 11:按生成 token 数归一化后的任务平均 API 调用次数。Beam search(beam=5)涉及显著更多的 API 调用,因为只有获胜 beam 的 token 被计为输出。
由控制层处理的 API 调用成本较低,即便在 896 个并发 inferlet 下,每次调用也低于 30 微秒。相比之下,由推理层处理的 API 调用开销更高,范围在 10–300 微秒之间,且随并发 inferlet 数量增加而上升。主要开销来自 Python 单线程的 API 调用反序列化,并发 inferlet 增多时尤为明显;IPC 边界跨越仅引入较小且稳定的额外延迟。采用 C++/Rust 的原生多线程推理层实现有望缓解该问题。
与 vLLM 等单体化系统相比,Pie 的细粒度 API带来了机会成本。单体化解码循环(如 vLLM)具有三项主要优势:(1)将输入 token 的嵌入与输出 token 的采样与 LLM 前向计算进行流水线化;(2)避免对输出 token 分布进行单独管理;(3)简化批处理调度。为量化这一成本,我们对 Pie 的编程模型进行了消融实验,创建了粒度更粗的自定义 API(如 forward_with_sampling)来模拟单体系统中的融合操作,并测量由此带来的性能提升。
在 32 个并发 inferlet 的实验中,结果汇总于表 3。与优势(2)和(3)相关的机会成本相对较小;相比之下,缺乏流水线化(优势(1))会带来更显著的延迟开销,约为 0.23–1.39 ms/ token。尽管如此,该开销相对于 Pie 的典型逐 token 延迟(5–60 ms)仍然较小。这揭示了一种权衡:对于高度延迟敏感的应用,引入专用 API 可以提升性能,但会牺牲一定的可组合性。
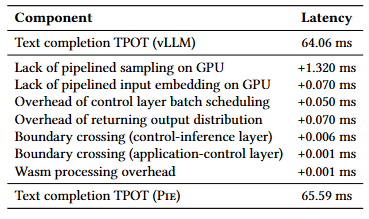 表 3:Pie 编程模型的机会成本。与 vLLM 相比,该开销相对于 Pie 的逐 token 延迟(17–65 ms)较小。
表 3:Pie 编程模型的机会成本。与 vLLM 相比,该开销相对于 Pie 的逐 token 延迟(17–65 ms)较小。
随着模型规模增大,Pie 的相对开销会降低,因为系统开销可被更长的计算时间摊薄。如表 4 所示(与 vLLM 对比的端到端每 token 输出时间,TPOT),在更大模型上,两者之间的性能差距会缩小。例如,在 8B 参数模型下,Pie 带来的 1.53 ms 开销仅占 vLLM 的 TPOT 的 2.4%。
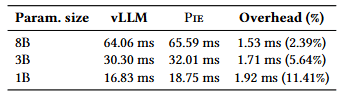 表 4:不同模型规模下文本补全任务的每输出 token 生成时间(TPOT)。更大的模型规模有助于摊薄 Pie 的开销。
表 4:不同模型规模下文本补全任务的每输出 token 生成时间(TPOT)。更大的模型规模有助于摊薄 Pie 的开销。
为展示自适应批处理调度(§6.1)的优势,我们将其吞吐量与三种基线策略进行了比较:不批处理(Eager)、基于队列长度的固定大小批处理(K-only),以及基于等待时间的超时批处理(T-only)。在 128 个并发 inferlet、调度器完全饱和的情况下,自适应策略表现最佳。如表 5 所示,与 Eager 基线相比,其吞吐量最高可提升 17×,并且相较 K-only 与 T-only 策略高出 8–40%。
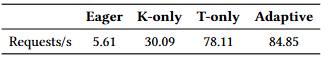 表 5:不同批处理策略下的吞吐量。采用 work-conserving 调度的自适应策略,相比不批处理(Eager)以及固定速率策略(K-only、T-only)实现了最高吞吐量。
表 5:不同批处理策略下的吞吐量。采用 work-conserving 调度的自适应策略,相比不批处理(Eager)以及固定速率策略(K-only、T-only)实现了最高吞吐量。
将控制权委托给用户提供的 inferlet,并允许网络 I/O,相较于闭环式服务扩大了攻击面。潜在风险包括侧信道泄露、资源耗尽(DoS),以及对 token 分布访问的滥用(例如协助 jailbreak 或模型抽取)。对安全性的全面讨论超出了本文范围,但对于 Pie 的商业化采用,系统加固至关重要。有前景的方向包括:基于能力的 I/O 控制、按 inferlet 的速率限制与配额,以及限制或混淆 logits 的暴露(例如 Top-K 上限)。
我们选择 WebAssembly(Wasm) 作为 inferlet 的运行时,以在隔离性、启动延迟与多租户可移植性之间取得平衡。其他替代方案在我们的目标下表现不佳:原生 OS 进程 提供的隔离较弱;容器(如 Docker)在频繁实例化 inferlet 时会引入冷启动与资源开销;嵌入式解释器(如 Lua)往往产生 FFI 开销且隔离性不足。实践中,Wasm 为 Pie 提供了最佳折衷。
目前,Pie 的控制层是一个集中式批处理调度器,向单一推理后端供给任务。真实部署需要跨越多个 GPU 节点,这带来了负载均衡、KvPage 局部性(放置/迁移)以及端到端 SLO 保障等挑战。因此,扩展 Pie 需要分布式协同、全局感知调度与缓存感知的放置策略,以及跨节点的容错机制。
支持细粒度可编程性需要三项架构变更:(1)集成可安全执行用户代码的运行时;(2)设计用于控制与资源管理的低层 API;(3)围绕 API 级 GPU 操作重新设计批处理调度。将这些能力回溯式加入现有服务栈,本质上将重现 Pie 的架构。尽管如此,更增量、粒度更粗且更契合现有设计的可编程层,仍是值得探索的未来方向。
当 KvPage 需求超过容量时,Pie 目前采用 FCFS 策略,终止最近启动的 inferlet 以释放资源。更丰富的策略有望提升公平性与效率:如按 inferlet 的配额、SLO/优先级感知的准入与抢占,以及通过 CPU–GPU 之间交换 KvPage 的受控过量配置。探索这些机制是有前景的未来工作。
Pie 建立在一系列可编程系统之上,这些系统横跨操作系统、网络与分布式框架,通过暴露细粒度接口将应用层控制与系统内部解耦——这是 Pie 应用于 LLM 服务领域的核心原则。
Pie 顺应了近期针对 LLM 工作流进行整体服务优化的趋势。值得注意的是,SGLang 与 Parrot 已引入一定的编程控制结构。SGLang 使用 fork/join/gen 等原语并通过 RadixAttention 优化共享生成路径;Parrot 则利用“语义变量”基于应用上下文改进 KV cache 复用。尽管它们为结构化生成与提示管理提供了有价值的抽象(部分覆盖 R1 与 R2),但仍受制于单体化生成过程,因而缺乏对低层资源(如单个 KV cache 页)、推理步骤序列(嵌入、注意力、采样)以及在生成过程中无缝集成任意 I/O的细粒度、直接控制——从而限制了其满足 R3 的能力。相比之下,Pie 通过 API 提供更低层、显式的控制,实现了超越这些高层抽象的定制能力。另一方面,也有工作通过并行化 LLM 函数调用或在等待调用完成时管理 KV cache来改进 LLM 与外部工具的交互效率以应对 R3。Pie 将这些策略作为用户定义程序来支持,避免了对服务系统内部的修改。
Pie 与近期的“LLM 编程”研究在概念上相似,后者主要沿两条方向发展:(1)基于形式文法的约束解码;(2)提示工程与编排框架。第一类包括 LMQL、Guidance、Outlines、XGrammar 与 AICI。这些系统通常在标准解码循环的约束内,通过 EBNF 文法或声明式约束来控制生成语义。值得注意的是,AICI 使用 WebAssembly 提供更高的灵活性。与之不同,Pie 使用图灵完备语言不仅指定“生成什么”,还指定“如何生成”。也就是说,Pie 对推理过程本身进行逐步控制——包括 tokenization、注意力、KV cache 管理、采样与 I/O——其可编程性超越了仅控制输出语义。第二类方向中,LangChain、LangFlow、DSPy、AutoGen 等框架以开发者易用性与输出质量为重点,简化代理工作流与提示优化。Pie 与这些系统正交且互补:它可以作为后端运行 inferlet(手工嵌入逻辑或由其抽象生成),从而使这些框架继承 Pie 的性能与 I/O 集成能力。
大量工作通过量化、并行化、GPU 内核优化与内存管理提升 Transformer 推理效率。Pie 在这些以效率为导向的技术之上,提供了可编程的 LLM 生成过程,与之形成互补。
Pie 代表了 LLM 服务向可编程性转变的范式跃迁。它超越了僵化的单体化设计,将 token 生成过程分解为模块化的 API 处理器,使用户提供的程序(inferlet)能够编排整个工作流,从而实现对 KV cache 管理、自定义解码流程以及外部计算与 I/O 的紧密集成的细粒度控制。我们的评估表明,这种可编程性使 Pie 能够实现从自定义注意力模式到代理式工作流在内的多种现代 LLM 技术。关键的是,Pie 在标准任务上保持了具有竞争力的性能,同时通过促进针对性优化,在复杂工作负载上显著改善了吞吐与延迟。我们的结果表明,可编程性是下一代 LLM 应用所需性能与灵活性的关键。