关于评估大语言模型(LLM)推理系统性能
发布于 • 作者: Amey Agrawal et al.
本文是On Evaluating Performance of LLM Inference Systems的译文。
大语言模型(LLM)推理系统的快速演进带来了显著的性能和效率提升。然而,我们的系统性分析表明,当前的评估方法往往存在根本性缺陷,常常表现为一些常见的评估反模式,这些反模式掩盖了真实性能特征,并阻碍了科学进展。通过对近期系统的全面审视,我们在三个关键维度上识别出反复出现的反模式:基线公平性(Baseline Fairness)、评估设置(Evaluation Setup)以及指标设计(Metric Design)。
由于 LLM 推理具有独特的特性,这些反模式尤为严重:其一,推理过程具有双阶段特性,即包含不同的 prefill 与 decode 操作;其二,需要处理高度异构的工作负载;其三,面向交互式使用时对时间有严格要求。我们表明,常见的反模式——例如将工程投入与算法创新混为一谈的不公平基线对比、无法代表生产环境的工作负载选择,以及掩盖生成停顿等重大性能波动的指标归一化方式——都会导致具有误导性的结论。
为应对这些挑战,我们基于分析提出了一份全面的检查清单,用于识别并避免上述反模式,从而实现稳健的 LLM 推理评估。为展示该框架的实际应用,我们提供了一个关于 推测式解码(speculative decoding) 的案例研究。这是一种令牌生成呈现突发性和非均匀性的技术,若采用这些反模式化的评估方法,极易被误读。我们的工作为评估方法学奠定了严格的基础,使得系统比较更具意义、结果更具可复现性,并最终通过将评估与真实世界需求对齐、超越常见反模式,加速 LLM 推理系统的真正进步。
在过去两年中,大语言模型(LLM)推理系统取得了显著进展。研究社区通过诸如连续批处理(continuous batching)、 分页注意力(paged attention) 以及 推测式解码(speculative decoding) 等创新手段,大幅提升了效率,实现了数量级更高的吞吐量和更低的延迟。开源框架和商业服务已将这些系统扩展到数百万规模,使强大的生成式人工智能得以普及。
然而,这种快速的技术进步已经超越了我们的评估方法学。我们对近期系统的系统性分析揭示了一个令人担忧的分化现象:尽管系统本身在前所未有的规模上迅速演进,但用于评估它们的方法却基本停滞不前。这种停滞导致了不一致性,掩盖了真实性能特征,并阻碍了科学进展。通过对顶级同行评审会议中具有影响力工作的全面考察,我们识别出 LLM 推理系统评估中一些一致存在的反模式。
这些反模式直接源于 LLM 推理服务所固有的复杂性和独特特征。具体而言,LLM 推理将用于处理提示词的、计算密集型的并行 prefill 阶段,与用于生成令牌的、受内存带宽限制的顺序 decode 阶段相结合,从而产生复杂的资源竞争和性能动态(双阶段推理)。此外,生产环境中的部署还面临极端的工作负载异构性:提示长度可能从几十到数万个令牌不等,输出长度各异,不同应用(例如交互式聊天与批量摘要)对延迟的严格程度也不相同,这使得恰当的工作负载选择至关重要。
用户体验往往高度依赖于延迟要求,例如首令牌时间(Time-To-First-Token, TTFT)以及稳定的令牌间时间(Time-Between-Tokens, TBT),而这些方面很容易被简单的端到端延迟指标所掩盖。进一步加剧问题的是模型架构的快速演进(例如 Grouped Query Attention(GQA)、Mixture-of-Experts(MoE)),这些变化不断转移性能瓶颈,并要求评估策略能够超越过时假设,具备更强的适应性。
要改进 LLM 推理系统,首先必须改进我们对它们的测量方式。本文提供了一个用于稳健评估实践的系统化框架,其核心是一份全面的检查清单,引导研究者关注诸如工作负载选择和指标设计等关键因素。该清单源自我们对常见陷阱的分析,为确保实验评估能够以符合真实世界需求的方式准确反映系统性能提供了具体指导。
为说明该方法框架的应用,我们以推测式解码为例进行了研究——这是一种流行的解码延迟优化技术,而天真的评估方法在此往往会失败。该分析作为一个实际示例,展示了我们的评估原则如何揭示那些本会被误导性统计数据所掩盖的性能特征。
我们在文献中识别出跨越三个维度的一致评估反模式——基线公平性、评估设置和指标设计——这些反模式直接源于上述挑战。这些反复出现的次优实践经常掩盖关键性能限制(如高调度延迟或生成停顿),并夸大新技术的感知收益。这些反模式既源于对基本评估原则的忽视(在 LLM 系统中尤为严重),也源于未能使评估方法适配此类系统的独特特性。
本文旨在通过以下方式建立严格的评估标准:
本节介绍典型的 LLM 推理流程、常用的推理性能度量指标,以及使 LLM 推理系统评估具有挑战性的若干独特属性。
LLM 推理包含两个不同阶段——prefill 阶段和 decode 阶段。在 prefill 阶段,系统处理用户输入的提示词,并生成第一个输出令牌。随后在 decode 阶段,输出令牌按顺序逐个生成:在某一步生成的令牌会被再次输入模型,用于生成下一步的新令牌,直到生成一个特殊的序列结束令牌为止。图 1 展示了这一自回归生成过程。
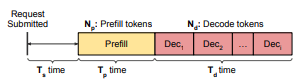
图 1: LLM 推理请求的结构示意图,展示了三个不同阶段:调度(Ts)、prefill 处理(Tp)以及 decode 生成(Td)。prefill 阶段并行处理 Np 个输入令牌,而 decode 阶段顺序生成 Nd 个输出令牌。每个 decode 令牌(Dec1、Dec2、…、Deci)均是逐个生成的。
在 decode 阶段的注意力计算中,还需要访问与此前所有已处理令牌相关的 KV(key 和 value)对。
LLM 推理性能常用的传统指标包括:
相较于传统的机器学习服务场景,LLM 推理系统的评估面临着更为独特的困难。这些困难源于推理过程的内在复杂性、多样化的应用需求,以及该领域的快速演进。
LLM 推理工作负载在 prefill 和 decode 两个阶段呈现出本质上不同的特征。prefill 阶段是计算受限型的,需要并行处理数百到数千个输入令牌,且计算复杂度呈二次增长;而 decode 阶段则是内存受限型的,每次仅生成一个令牌,并由于 KV-cache 的需求而具有密集的内存访问模式。这种双重特性导致了复杂的性能动态,以及请求之间资源利用率的高度可变性。
此外,prefill 阶段随输入长度呈二次增长的时间复杂度,在用户对一致性能的期望与实际可计算性之间形成了根本张力。例如,尽管用户可能期望不同输入具有相近的响应时间,但一个包含 32K 令牌的提示词所需计算量是 16K 令牌提示词的 4 倍。这种可变的成本结构使得定义有意义的性能目标变得极具挑战。
不同的 LLM 应用在输入特性和性能优先级上存在巨大差异,使得“什么是好的性能”这一问题难以界定。我们对生产环境追踪数据的分析(见表 1)显示,不同应用的请求长度分布差异显著:在 Azure LLM Inference 2024 数据集中,代码类应用与对话类应用的中位提示词长度相差 2×,而中位输出长度则相差 5×。此外,kimi.ai 接收到的中位提示词长度约为 Azure 对话类应用的 6×。
表 1:来自公开生产追踪数据的统计信息
----------------------------------------------------------
Trace | Prefill tokens | Decode tokens | P:D ratio
| Median IQR P99 | Median IQR P99 | Median IQR
Azure Code 2024 | 1928 2393 7685 | 8 15 276 | 238 686
Azure Conv 2024 | 928 1811 6683 | 41 94 694 | 21 63
Mooncake | 6345 4243 61616 | 30 343 898 | 163.5 602
----------------------------------------------------------
在性能需求方面,代码补全工具可能更强调严格的 TTLT 保证,并可容忍一定程度的抖动;而对话式智能体则需要稳定、较低的 TBT 以维持自然的交互节奏,可能牺牲绝对吞吐量。长文本生成往往更关注整体吞吐能力(容量或较低的平均 TPOT),而非即时响应性(TTFT)。这些不同需求导致了不同的优化目标和指标选择,同时对延迟方差的敏感度也不尽相同。例如,高级语音接口可能接受较低的令牌生成速率,但几乎无法容忍会破坏流畅感知的生成停顿。
LLM 领域的快速创新进一步加剧了评估难度。诸如 Mixture of Experts (MoE) 和 Grouped Query Attention (GQA) 等新架构,展现出与传统稠密 Transformer 不同的性能特征。例如,GQA 模型可显著降低(如 4–8×)KV cache 的内存占用,从而缓解促使 PagedAttention 等技术出现的主要瓶颈。这类进展可能使基于旧架构的评估假设变得具有误导性甚至失去意义。
与此同时,新兴应用不断引入新的性能需求和使用模式,要求评估方法学必须持续演进,才能在不断变化的 LLM 生态中保持有效性并准确反映系统性能。这种多样性进一步凸显了稳健且可适应的评估方法学的必要性。
表 2:近期 LLM 推理系统中评估实践的评估
表 2 对近期 LLM 推理系统中的评估实践进行了系统性分析。我们的分析从三个关键维度展开:基线设置(baseline setup)、评估方法(evaluation methodology)以及指标设计(metric design)。表中使用对勾(✓)表示某项实践被采用,使用叉号(×)表示该实践缺失。第 5 节详细介绍了具体的评估流程。
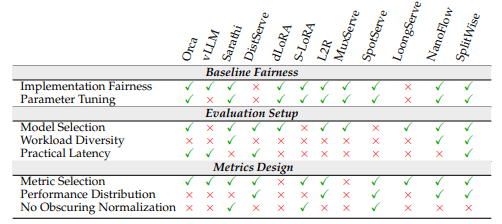
对复杂系统进行公平比较需要对实现细节和配置给予极其细致的关注。忽视这些因素会导致常见的反模式,使得观察到的差异被错误归因。
LLM 推理系统是高度复杂的工程产物,旨在最大化加速器利用率。底层实现上的差异(例如:调度开销、通信协议、低层优化)会对性能产生显著影响——已有研究表明,CPU 开销可能贡献了 超过 50% 的延迟。未能将算法贡献与系统工程能力区分开来,是一种常见的反模式。这会使识别新技术的真实收益变得困难,甚至可能误导研究方向。
尽管 DistServe 和 LoongServe 等系统在评估时会与标准基线(如 vLLM、DeepSpeed-MII)进行比较,但它们往往缺乏能够严格区分算法增益与实现特定优势的评估。相比之下,NanoFlow 提供了一个透明度极高的示范案例。其报告通过 nano-batching 技术获得了 1.91× 的吞吐量提升,但其细致的消融实验显示,大部分提升来自系统级优化;当隔离后,核心算法思想仅贡献了 16%。这种对真实创新至关重要的详细拆解在实践中仍然十分罕见。该反模式使实现差异掩盖并不准确地放大了算法改动的影响。
评估检查清单
- ✓ 实现公平性:基线是否以可比方式实现?
- 如果不是,是否使用了微基准测试或消融实验来隔离算法增益与系统实现差异?
LLM 服务系统暴露了丰富的配置空间(例如:批大小、资源分配比例、调度策略),可针对不同场景进行优化。诸如预填充/解码解耦等技术,需要对资源分配进行精细调优才能达到最佳性能。一种常见反模式是:新系统经过了大量调优,而基线系统却仅使用默认或随意选择的参数。即便是看似微小的配置差异,也可能导致显著的性能变化,从而使比较结果失效。
例如,在 DistServe 和 LoongServe 中与 DeepSpeed-MII 的 chunked prefill 进行比较时,并未报告根据具体工作负载对基线的关键 chunk 大小参数进行调优,尽管已有工作表明该参数对性能有显著影响。相反,Orca 展示了良好实践:其在不同批大小下对基线(FasterTransformer (fas))进行了细致评估,从而确保了更公平的比较。未对基线投入同等调优努力,是一种关键的公平性反模式。
评估检查清单
- ✓ 参数调优:是否为所提系统和基线系统记录了所有关键性能配置参数?
- ✓ 基线参数是否针对评估设置进行了恰当调优?
模型选择、工作负载以及运行约束的选择会显著影响评估结果。使用不代表当前技术水平或真实世界使用场景的设置,构成了另一类反模式。
LLM 生态系统发展迅速。诸如 GQA 和 MoE 等架构,相较于较早的标准 MHA(Multi-Head Attention)模型,具有不同的性能瓶颈。尤其是,GQA 模型所需的 KV cache 内存减少了 4–8×。仅在 MHA 模型上评估技术,特别是内存优化类技术,是一种反模式,因为这可能针对的是在最先进模型中已不再突出的瓶颈。某些技术在 MHA 模型上表现出显著收益,仅仅是因为其内存占用更大;而在 GQA 模型上,这种优势可能会缩小甚至消失。
DuoAttention 树立了良好先例:其在 MHA 和 GQA 模型上同时评估 KV cache 压缩效果,结果显示在更现代的架构上收益明显减弱(2.55× vs. 1.67×),为结果提供了关键背景。评估应当反映当代模型架构,以确保所提出的技术确实解决了相关且现实的瓶颈问题。
评估检查清单
- ✓ 模型选择:所评估的模型是否反映了当前最先进水平?
- ✓ 关键技术是否在不同模型架构上进行了评估,以覆盖其影响可能显著变化的情形?
生产环境中的 LLM 服务支持多样化应用,其工作负载特征各不相同(例如:代码补全——短输入/输出、低延迟需求;聊天——中等长度、输出可变;摘要——长输入/输出)。一种反模式是:系统评估主要依赖单一来源数据集(如仅包含短对话的 ShareGPT),或依赖合成工作负载,且通常输入长度受限(例如平均 1024 tokens)。这种狭窄的关注范围容易忽略那些只在长序列、不同交互模式(如多轮对话)或高请求波动下才会显现的关键性能行为。
已有研究表明,为某一种工作负载进行优化,可能会导致在另一种工作负载上出现高达 2× 的性能下降。因此,跨越多样化且真实的工作负载进行评估,对于理解系统的真实优势、劣势以及泛化能力至关重要。
评估检查清单
- ✓ 工作负载多样性:评估是否超越了单一数据集或合成轨迹?
- ✓ 是否涵盖了聊天、代码、摘要等多种应用,以及它们各自特有的输入/输出长度分布和交互模型?
追求算法层面的进步固然重要,但若未将改进结果放在实际延迟需求的背景下进行呈现,同样是一种反模式。用户感知的是绝对延迟(如 TTFT、TBT),而不仅是相对提升或归一化指标。近期的低延迟优化系统表明,某些早期工作所声称的吞吐提升在实践中难以实现,因为它们依赖于尾延迟不可接受的运行点。
以 LoongServe 为例,其针对超长上下文(最高可达 500K tokens)提出了优化方案。尽管在技术上颇具吸引力,但评估中报告的每输入 token 的归一化延迟达到了数百毫秒。这意味着其绝对 TTFT 达到数千至数万秒,远远超出任何交互式应用的可接受阈值。类似情况在多项工作中均有体现:论文中报告的归一化延迟指标,掩盖了绝对延迟跨越多个数量级增长的事实。
DistServe 展示了良好实践:其明确设定了与应用相关的延迟边界(SLO),并在这些约束内进行性能评估。任何性能改进,都必须在目标应用可接受的延迟区间内得到验证。
评估检查清单
- ✓ 实际延迟边界:所报告的改进是否在适合目标应用的延迟边界内实现(例如
TTFT、TBT的 SLO)?- ✓ 报告的指标与用户实际体验到的绝对延迟之间的关系是否清晰明确?
指标的选择与呈现方式会深刻影响结论。与指标选择、聚合和归一化相关的若干反模式,可能会掩盖关键性能细节。
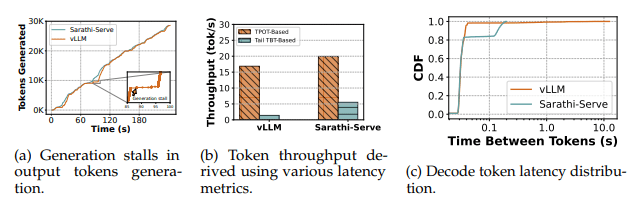
Figure 2: 以 vLLM 和 Sarathi-Serve 为例,展示传统指标的局限性。 (a) 实际的 token 生成过程中可能存在显著的停顿。 (b) 像 TPOT 这样的平均指标会掩盖这些停顿,从而高估有效吞吐量。 (c) 完整的 TBT 分布揭示了仅看尾延迟分析所忽略的细节(例如 P85 与 P99 的权衡)。
LLM 推理工作负载在请求级别的异质性使得使用传统指标进行评估变得困难。每个请求在提示长度、输出长度、延迟敏感性以及资源需求等方面都可能存在巨大差异。这种复杂性导致社区在评估 LLM 推理性能时形成了自然碎片化:不同论文采用不同指标,使得进展难以追踪、系统难以公平比较。更重要的是,在某些情况下,所选指标并不能很好地反映真实的用户体验。
例如,dLoRA 报告了平均延迟,其计算方式是将每个请求的端到端延迟求和后,再除以输出 token 的总数。尽管这种指标计算方便,但它并不对应任何用户真实经历的延迟。此外,这种做法还可能掩盖严重影响用户体验的尾延迟问题,因此并不适合用于稳健评估。
评估检查清单
- ✓ 指标选择:所选指标是否被广泛使用并易于理解?
- ✓ 对于新指标,是否清楚解释并论证了其与用户感知性能之间的关系?
只关注汇总统计量(如中位延迟),而忽略完整的性能分布,是一种普遍存在的反模式。早期系统主要报告中位延迟。后续研究揭示,这些系统存在较高的尾延迟,从而阻碍了生产部署。然而,仅仅转而关注尾延迟(如 P99)同样是不完整的。
如 Figure 2c 所示,在 Arxiv Summarization 数据集上比较 Sarathi-Serve 与 vLLM,可以观察到一种权衡关系:Sarathi-Serve 在 P99 延迟上更优,但在 P90 附近却表现出更高延迟。这类关键权衡对于理解系统在负载下的行为,以及为特定 SLO 选择合适系统至关重要,而它们只有在查看完整性能分布(或至少 P50、P90、P99 等多个关键分位点)时才能显现。
评估检查清单
- ✓ 性能分布:评估是否呈现了完整的延迟分布(如 CDF),或至少提供了 P50、P90、P99 等关键分位点,而非仅给出平均值或中位数?
- ✓ 分析是否揭示了分布中不同位置的性能权衡?
归一化是一种常见做法,但在 LLM 推理中,不当使用可能形成反模式,从而掩盖面向用户的性能问题。诸如归一化延迟(如 (Ts + Tp + Td) / Nd)和 TPOT(Td / Nd)等指标十分常见,但它们可能会掩盖固定或近似固定的开销,尤其是调度延迟(Ts)。
考虑一个示例:两个请求分别生成 10 和 1000 个 token,二者都经历了 10s 的调度延迟,且每个 token 的生成时间为 20ms。归一化延迟差异巨大(1.02 s/token vs. 0.03 s/token),错误地暗示了用户体验存在巨大差别。实际上,两个用户都承受了同样不可接受的 10 秒初始等待。归一化会根据(可变的)输出 token 数量稀释固定延迟。
Figure 2 的实证结果证实了这一点:在 Arxiv Summarization 上评估 Sarathi-Serve 与 vLLM 时,vLLM 在 60% 的请求中存在超过 25 秒的调度延迟,但这一关键差异在归一化延迟图中几乎不可见。
同样地,TPOT(平均解码时间)也会掩盖时间上的不一致性。如 Figure 2a 所示,两个系统可能具有相同的 TPOT,但一个系统平滑生成 token,而另一个则以突发方式生成,并在其间出现长时间停顿。这些被平均值隐藏的停顿,会在交互式应用中严重降低用户体验。因此,尽管归一化具有一定价值,但若仅依赖归一化指标而不检查原始、绝对的性能特征(如 Ts 和 TBT 分布),就是一种严重的反模式。
评估检查清单
- ✓ 避免掩盖性能的归一化:在使用归一化指标(如归一化延迟、TPOT)时,是否同时检查了原始性能特征?
- ✓ 是否独立分析了关键时间因素,如调度延迟(
Ts)和 token 生成停顿(TBT 方差)?- ✓ 评估是否考虑到归一化可能掩盖原始测量中已显现的、面向用户的性能问题?
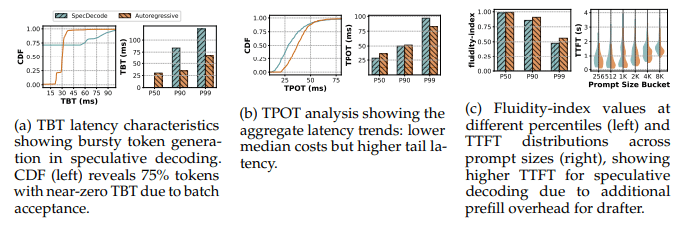
Figure 3: 推测解码与自回归性能对比(0.25 QPS,ShareGPT4,Llama-3 70B,4×H100)。
该图强调了常见评估反模式的影响:
(a) 具有误导性的 TBT 分布;
(b) 相互矛盾的 TPOT 趋势(中位数 vs. 尾部);
(c)(右)由于草稿模型额外预填充开销而被掩盖的 TTFT 影响。
这些结果表明,孤立使用传统指标会错误刻画推测解码的权衡;需要引入如 Fluidity Index 等一致性指标,才能进行准确评估。
为说明评估反模式在实践中的具体影响以及严格方法学所带来的收益,我们研究了推测式解码(speculative decoding)——一种流行的延迟优化技术。该技术的令牌生成延迟具有非均匀性,使其难以用标准指标进行评估。推测式解码使用一个较小的 draft 模型来预测多个未来令牌,然后由更大的主模型并行验证。这会导致解码延迟的分散:当验证成功时,令牌会以几乎瞬时的方式成批到达;而当验证失败时,则需要同时付出 draft 生成与验证的代价,最终只生成一个令牌,从而产生明显延迟。
使用标准指标来评估该技术,往往会体现出前文(第 3 节)讨论的反模式,从而导致不完整甚至误导性的结论。我们的分析(部分结果如图 3 所示)揭示了这些局限性:
该案例研究生动地表明,仅聚焦于单个、传统指标会导致相互矛盾的结论,这正是第 3 节中所识别评估反模式的典型表现。那么,我们究竟该相信哪一个指标?答案是:需要一种更加整体化的评估方法,以避免这些反模式。
例如,引入能够在突发生成情况下刻画生成一致性的指标(如 Agrawal 等提出的、基于截止时间的 Fluidity Index),可以揭示更为细致的性能图景。尽管推测式解码通常能提升平均令牌生成速率(体现在较低的中位 TPOT 上),但这类基于截止时间的指标会暴露其引入的波动性,以及在验证失败时用户可感知停顿概率的增加(这也解释了更高的 P99 TPOT)。这凸显了平均速度与生成一致性之间的关键权衡,而这一权衡对对停顿高度敏感的交互式应用尤为重要。整体性能表现还强烈依赖于 draft 模型的准确率以及典型响应长度:当生成序列更长时,初始 prefill 开销被摊薄,收益才会更加明显。
LLM 推理系统的演进速度已经超过了我们有效评估它们的能力,从而导致了报告性能与真实用户体验之间的关键性反模式。通过对近期系统的系统性分析,我们识别出评估方法学中反复出现的问题,涵盖基线公平性、实验设计和指标选择等方面。这些问题在 LLM 系统中尤为突出,其根源在于推理的双阶段特性、工作负载的高度异构性以及严格的延迟要求。
我们提出的综合评估检查清单为研究人员提供了进行有意义性能评估的关键指导。通过对推测式解码的案例研究可以看到,遵循正确的方法学能够揭示细微而重要的性能权衡,而这些权衡往往会被传统指标所掩盖。随着该领域持续快速发展,这些方法学原则为实现更有意义的系统比较、可复现的实验结果,以及真正反映真实世界性能需求的服务系统奠定了基础,最终确保论文中报告的改进能够转化为真实的用户体验提升,从而加速整个领域的进步。