引言
本文是How Uber Serves over 150 Million Reads per Second from Integrated Cache with Stronger Consistency GuaranteesBlog的阅读记录。
回顾
前文中我们描述了CacheFront的整体架构。
Read
读操作在查询引擎层被拦截,首先从Redis获取数据,未找到的数据会直接从存储引擎获取,并随后写入缓存以保持缓存活跃。读取结果随后被流式合并返回。
Write
由于存在条件更新,写操作不会被拦截。因为我们不了解查询执行后哪些行会被改变或已经改变,也就无法确认哪些缓存需要失效。
我们依赖TTL和Flux(一个CDC服务)来实现缓存失效。
问题
- TTL和CDC的数据一致性保证不强。
- 通过增加TTL使缓存更有效导致了更多不一致的值。
不一致
不一致表现为陈旧值(Stale Value),其存在有几种原因:
- 并发缓存填充(Racing cache fills):并发读写时不同进程尝试为该行缓存不同的值。在CacheFront中不是问题,因为使用了Lua脚本将写入的新条目与当前缓存的条目进行去重(基于行时间戳)。
- 缓存失效延迟(Cache invalidation delays):缓存失效存在延迟,因为Flux为异步进程。
- 缓存失效失败(Cache invalidation failures):Redis节点反应迟缓/无响应,导致多次尝试失效仍然失败,直到TTL过期而被移除。
- 缓存从从节点补充(Cache refills from followers):缓存未命中时通过读取一个落后于Leader节点的Follower补充。CacheFront允许选择策略:
- 从Leader补充增加一致性。
- 从Follower补充实现更好负载分布。
总结,不一致表现为:
- 读取-写入不一致性(Read-own-writes inconsistency):数据被读取,缓存后又被覆盖,在后续读取时仍可能返回旧数据。
- 读取-写入插入不一致性(Read-own-inserts inconsistency):当启用负缓存时,只要负缓存存在在缓存中,就会返回未找到,可能会破坏服务业务的假设。
缓存陈旧程度
即使使用TTL为五分钟,DB中行的时间戳与当前缓存的行时间戳的差值仍然可以很高(理论无界)。
因为假设一年前写入行数据,然后在当前时间进行了一次读-修改-写入操作,由于初始缓存未命中,该行数据从DB中读取随后被缓存,但是在修改后的行写回数据库时,Flux失效失败了,所以在TTL的时间范围内读取会一直读到一年前的数据。
更改条件更新流程
总结:缓存无法与请求同步失效的主要原因是条件更新,即无法知道事务中哪些行被更新并需要失效。
通过两个原则重新设计了写流程:
- 确保所有删除操作都是软删除,并设置墓碑,墓碑标记的行由异步删除任务稍后回收。
- 切换到使用严格单调时间来分配MySQL会话时间戳(精确到微秒),使其在所属的存储节点和Raft组内唯一。
事务执行中:
-
事务执行时,所有更新的行会打上 当前事务的唯一时间戳。
-
在 COMMIT 之前,系统执行一个轻量级查询:
- 根据时间戳索引,快速找出本事务中所有被修改的行(包括标记墓碑的行)。
- 由于数据已经在 MySQL 存储引擎的缓存里,所以查询成本很低。
-
得到这些被修改的行键后,将它们返回给查询引擎,用于缓存失效。
因此,条件更新也能准确知道哪些行真的被更新了。
更改缓存失效逻辑
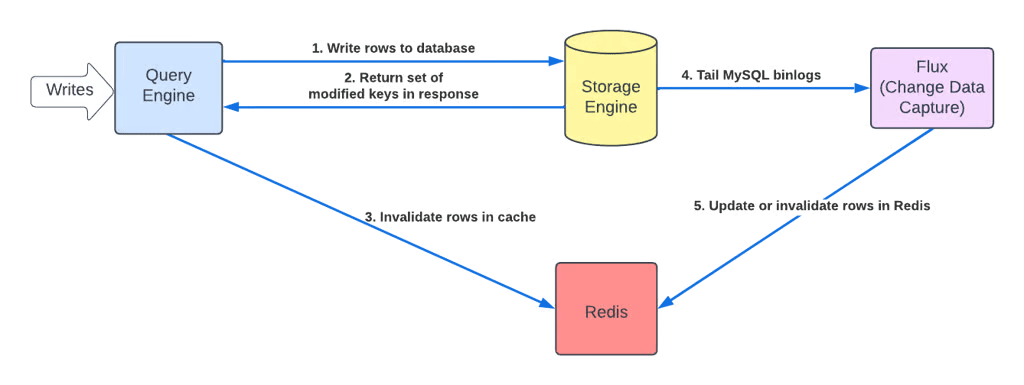
查询引擎拦截每个写入API,注册回调,在存储引擎的请求返回时被调用。存储引擎除了返回受事务影响的行键集合外同时返回相关的会话时间戳。在回调中可以失效Redis之前缓存的任何条目,并用失效标记覆盖。
在后台Flux仍运行,跟踪binlog并异步方式缓存填充。于是现在有三种方法来保证一致性:TTL、Flux跟踪、查询引擎曾写入路径。
同步/异步
新流程可以同步/异步执行。
- 同步:缓存在请求上下文中失效(向客户端返回前执行),跟高的延迟,更适合read-own-writes & read-own-inserts。即使请求成功但失效失败,仍向客户端返回成功。
- 异步:避免了额外延迟,但一致性稍弱。
通过存储引擎返回会话时间戳,我们可以在缓存填充条目和查询引擎及Flux生成的失效标记之间正确去重,并弃用先前使用机器时间的方案。
缓存更适合读多些少场景(20:1 ~ 100:1),如果写请求本身占比低,引入额外失效开销并不会显著增加系统负载。
两篇文章总体总结
背景
Uber 内部使用 Docstore(基于 MySQL 构建的分布式数据库)来支撑业务。它存储数十 PB 数据,每秒处理上千万请求。随着业务和微服务依赖的复杂度增加,Docstore 在 低延迟、高吞吐量读请求 场景中面临挑战:
- 磁盘 IO 优化有限,无法无限提升性能
- 垂直扩展成本高且有瓶颈
- 水平扩展复杂,热分区/热键问题难解决
- 读写比例极度不均衡(读远高于写),导致读负载巨大
- 成本成倍增加,难以维持
传统方案是使用 Redis 缓存,但由各团队分散管理,存在 缓存一致性、失效、跨区域复制 等复杂问题。
因此 Uber 构建了 CacheFront:一个与 Docstore 深度集成的缓存层,由数据库团队统一维护,透明地服务所有微服务。
CacheFront 第一阶段(2024 年)
设计目标
- 降低数据库层的扩展需求和成本
- 显著降低延迟(P50 / P99)并平滑突发请求
- 透明集成到 Docstore 客户端(无需应用改造)
- 去中心化缓存逻辑 → 统一由 Docstore 团队提供
- 独立水平扩展缓存层
架构与机制
-
查询拦截:在 Query Engine 层集成 Redis 缓存,先查缓存,缓存 miss 再读存储引擎并回填缓存。
-
缓存一致性:
- 基本 TTL(默认 5 分钟)
- 借助 Flux(CDC 服务) 实时订阅 MySQL binlog 进行缓存失效/更新
- 使用 Lua 脚本和时间戳避免缓存写入旧数据(写去重)
- 提供 API 支持强一致需求(如“读自己刚写”)
-
扩展与容错:
- 跨区域 cache warming:通过复制缓存 key 触发远端缓存预热,避免 failover 时全量打爆数据库
- 负缓存(Negative Caching):缓存不存在的数据,减少重复查库
- Redis 分片:基于 partition key 分片,降低单集群压力,避免缓存失效时单库被打爆
- 熔断器 & 自适应超时:提升容错性,避免坏节点拖慢请求
- Compare Cache 模式:在线比对缓存与数据库,量化一致性(达 99.99%)
效果
- 延迟显著下降:P75 ↓ 75%,P99.9 ↓ 67%
- 大规模应用场景:单用例 6M RPS,缓存命中率 99%+,只需 ~3K Redis 核心(而非 ~60K DB 核心)
- 整体支持 40M+ QPS,极大缓解数据库负载并节省成本
CacheFront 第二阶段(2025 年)
随着规模扩展(4 倍以上,峰值 150M+ RPS),一致性需求更强,Uber 进一步改进:
问题与挑战
- TTL 与 CDC 带来最终一致性 → 部分场景不能接受
- TTL 越大 → 命中率高,但过期数据更多
- 缓存失效延迟/失败:Flux 重启或 Redis 异常导致数据长时间不一致
- Follower 回填:从延迟的副本读取可能缓存旧值
改进点
-
写路径缓存失效
-
重大突破:通过改造存储引擎,支持在事务提交前查询所有被更新的 row key(利用 软删除 + 单调时间戳)
-
Query Engine 在收到写事务返回时直接生成失效标记并写入 Redis
-
Flux 仍保留作为异步保障 → 形成 TTL + Flux + 写路径失效 的三重保障
-
支持同步或异步失效:
- 同步:牺牲一点写延迟,保证 读自己写
- 异步:降低写延迟,稍弱一致性
-
一致性增强
- 利用存储层生成的 commit timestamp 去重缓存写入和失效标记 → 消除显式 API,透明化强一致
- 提升缓存命中率并避免过度失效
-
可观测性:Cache Inspector
- 基于 Flux 延迟 1 分钟对比 binlog 与缓存,输出一致性指标(陈旧率、staleness 分布等)
- 帮助验证 TTL 调整的影响,并推动 TTL 增加至 24 小时,命中率提升至 99.9%+
整体成果
总体结论
Uber 通过 CacheFront 构建了一个深度集成 Docstore 的分布式缓存体系,逐步解决了分布式缓存的核心难题:
- 性能:超低延迟、百万级 QPS
- 扩展性:可独立水平扩展,跨区高可用
- 一致性:从最终一致性 → 亚秒级一致性 → 写路径强一致
- 可观测性:实时度量陈旧率,指导优化
- 成本:以低成本 Redis 集群替代高成本数据库扩容
最终,CacheFront 成为 业界领先的数据库集成缓存系统,支撑 Uber 核心业务在 超大规模读密集场景 下的稳定运行。