Stripe 的文档数据库如何在零停机数据迁移的情况下实现 99.999% 的可用性
发布于 • 作者: Suraj Narkhede
本文是How Stripe’s document databases supported 99.999% uptime with zero-downtime data migrations的原文+翻译
In 2023, Stripe processed $1 trillion in total payments volume, all while maintaining an uptime of 99.999%. We obsess over reliability. As engineers on the database infrastructure team, we provide a database-as-a-service (DBaaS) called DocDB as a foundation layer for our APIs.
2023 年,Stripe 处理了 1 万亿美元的支付总额,同时保持了 99.999%的运行时间。我们对可靠性有着极致的追求。作为数据库基础设施团队的工程师,我们提供了一种名为 DocDB 的数据库即服务(DBaaS),作为我们 API 的基础层。
Stripe’s DocDB is an extension of MongoDB Community—a popular open-source database—and consists of a set of services that we built in-house. It serves over five million queries per second from Stripe’s product applications. Our deployment is also highly customized to provide low latency and diverse access, with 10,000+ distinct query shapes over petabytes of important financial data that lives in 5,000+ collections distributed over 2,000+ database shards.
Stripe 的 DocDB 是 MongoDB Community 的扩展——一个流行的开源数据库,由我们内部构建的一组服务组成。它为 Stripe 的产品应用每秒处理超过 500 万次查询。我们的部署高度定制化,以提供低延迟和多样化的访问,在分布在 2000 多个数据库分片中、包含 5000 多个集合、存储着 PB 级重要金融数据的 10,000 多次不同查询形状上运行。
We chose to build DocDB on top of MongoDB Community because of the flexibility of its document model and its ability to handle massive volumes of real-time data at scale. MongoDB Atlas didn’t exist in 2011, so we built a self-managed cluster of MongoDB instances running in the cloud.
我们选择在 MongoDB Community 上构建 DocDB,是因为其文档模型的灵活性以及处理大规模实时数据的能力。2011 年时 MongoDB Atlas 还不存在,所以我们构建了一个在云端运行的 MongoDB 实例自管理集群。
At the heart of DocDB is the Data Movement Platform. Built originally as a horizontal scaling solution to overcome vertical scaling limits of MongoDB compute and storage, we customized it to serve multiple purposes: merging underutilized database shards for improved utilization and efficiency, upgrading the major version of the database engine in our fleet for reliability, and transitioning databases from a multitenant arrangement to single tenancy for large users.
DocDB 的核心是数据迁移平台。最初作为一项水平扩展解决方案构建,旨在克服 MongoDB 计算和存储的垂直扩展限制,我们将其定制化以实现多种功能:合并未充分利用的数据库分片以提高利用率和效率,升级集群中数据库引擎的主版本以增强可靠性,以及将数据库从多租户架构迁移到单租户架构以服务大型用户。
The Data Movement Platform enabled our transition from running a small number of database shards (each with tens of terabytes of data) to thousands of database shards (each with a fraction of the original data). It also provides client-transparent migrations with zero downtime, which makes it possible to build a highly elastic DBaaS offering. DocDB can split database shards during traffic surges and consolidate thousands of databases through bin packing when traffic is low.
数据迁移平台使我们能够从运行少量数据库分片(每个分片包含数十 TB 数据)过渡到运行数千个数据库分片(每个分片仅包含原始数据的一小部分)。它还提供对客户端透明的零停机迁移,这使得构建高度弹性的 DBaaS 服务成为可能。DocDB 可以在流量高峰时拆分数据库分片,并在流量低谷时通过装箱算法整合数千个数据库。
In this blog post we’ll share an overview of Stripe’s database infrastructure, and discuss the design and application of the Data Movement Platform.
在本博客文章中,我们将分享 Stripe 数据库基础设施的概述,并讨论数据迁移平台的设计和应用。
When Stripe launched in 2011, we chose MongoDB as our online database because it offered better developer productivity than standard relational databases. On top of MongoDB, we wanted to operate a robust database infrastructure that prioritized the reliability of our APIs, but we could not find an off-the-shelf DBaaS that met our requirements:
当 Stripe 于 2011 年启动时,我们选择了 MongoDB 作为我们的在线数据库,因为它比标准关系型数据库更能提高开发者的生产力。在 MongoDB 的基础上,我们希望运营一个强大的数据库基础设施,优先考虑我们 API 的可靠性,但我们找不到一个能满足我们要求的现成 DBaaS:
The solution was to build DocDB—with MongoDB as the underlying storage engine—a truly elastic and scalable DBaaS, with online data migrations at its core.
解决方案是构建 DocDB——以 MongoDB 作为底层存储引擎——一个真正弹性且可扩展的 DBaaS,其核心是支持在线数据迁移。
Product applications at Stripe access data in their database through a fleet of database proxy servers, which we developed in-house in Go to enforce concerns of reliability, scalability, admission control, and access control. As a mechanism to horizontally scale, we made the key architectural decision to employ sharding. (If you want to learn more about database sharding, this is a helpful primer.)
Stripe 的产品应用通过一组数据库代理服务器访问其数据库中的数据,这些代理服务器是我们使用 Go 语言内部开发的,以实现可靠性、可扩展性、准入控制和访问控制。作为水平扩展的机制,我们做出了一个关键的架构决策,即采用分片技术。(如果你想了解更多关于数据库分片的知识,这篇入门指南会很有帮助。)
Thousands of database shards, each housing a small chunk of the cumulative data, now underlie all of Stripe’s products. When an application sends a query to a database proxy server, it parses the query, routes it to one or more shards, combines the results from the shards, and returns them back to the application. 成千上万的数据库分片,每个分片存储着数据的一小部分,现在支撑着 Stripe 的所有产品。当应用程序向数据库代理服务器发送查询时,它会解析查询,将其路由到一个或多个分片,合并来自分片的结果,并将结果返回给应用程序。
But how do database proxy servers know which among thousands of shards to route the query to? They rely on a chunk metadata service that maps chunks to database shards, making it easy to look up the relevant shards for a given query. In line with typical database infrastructure stacks, change events resulting from writes to the database are transported to streaming software systems, and eventually archived in an object store via the change data capture (CDC) pipeline. 但是数据库代理服务器如何知道在成千上万个分片中将查询路由到哪一个?它们依赖于一个分片元数据服务,该服务将分片映射到数据库分片,从而可以轻松查找给定查询的相关分片。与典型的数据库基础设施堆栈一致,由于写入数据库而引起的变更事件通过变更数据捕获(CDC)管道传输到流式软件系统,并最终存档到对象存储中。
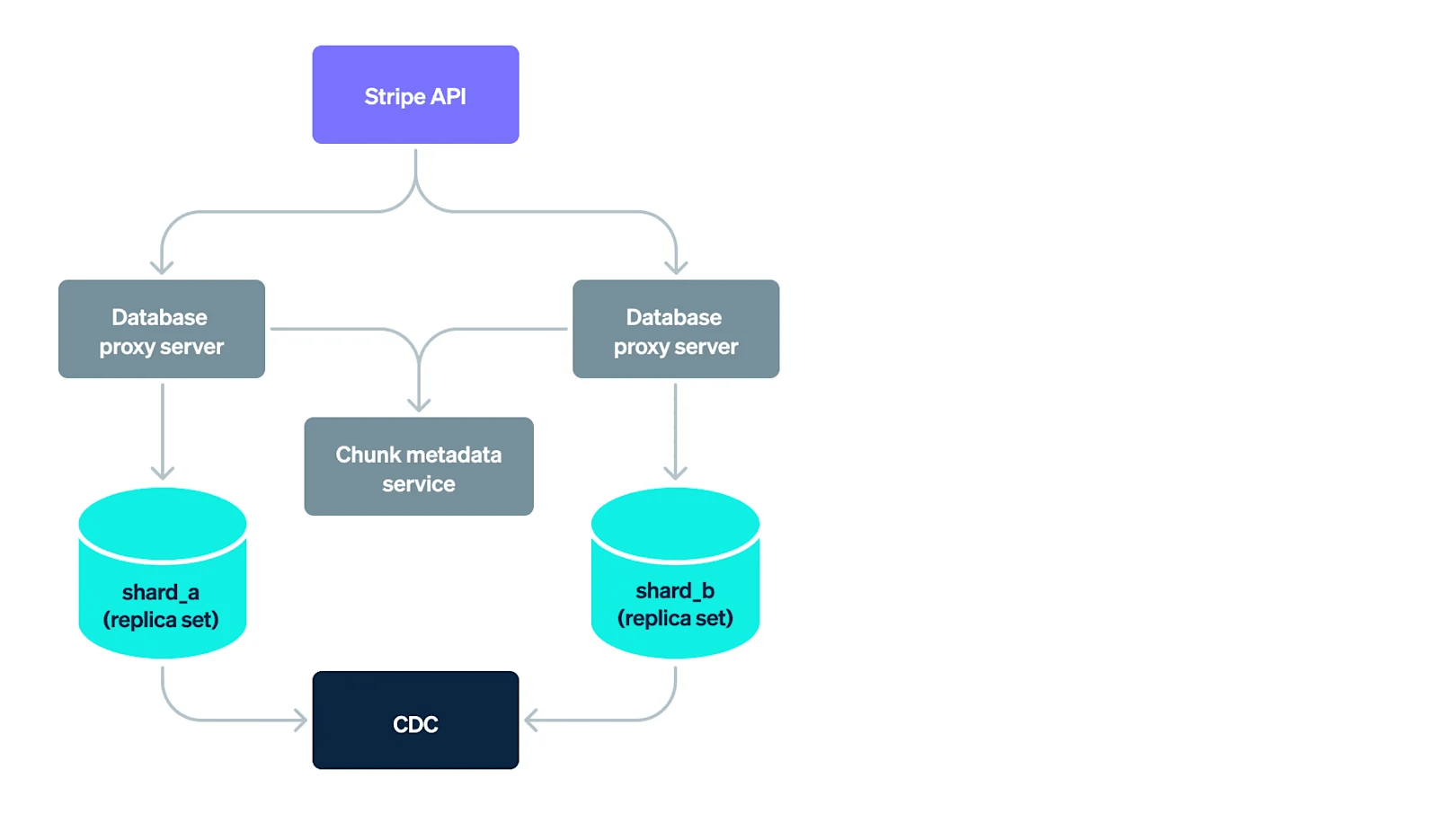
High-level overview of Stripe’s database infrastructure
Stripe 数据库基础设施的高层次概述
At the product application level, teams at Stripe use the in-house document database control plane to provision a logical container for their data—referred to as a logical database—housing one or more DocDB collections, and each comprising documents that have a related purpose. Data in these DocDB collections is distributed across several databases (referred to as physical databases), each of which is home to a small chunk of the collection. Physical databases on DocDB live on shards deployed as replica sets that comprise a primary node and several secondary nodes with replication and automated failover.
在产品应用层面,Stripe 的团队使用内部文档数据库控制平面为其数据配置一个逻辑容器——称为逻辑数据库——该容器包含一个或多个 DocDB 集合,每个集合包含具有相关用途的文档。这些 DocDB 集合中的数据分布在多个数据库(称为物理数据库)上,每个物理数据库都包含集合的一小部分。DocDB 上的物理数据库运行在分片中,这些分片以副本集的形式部署,每个副本集包含一个主节点和多个从节点,具备复制和自动故障转移功能。
 A sharded collection 一个分片集合
A sharded collection 一个分片集合
In order to build a DBaaS offering that is horizontally scalable and highly elastic—one that can scale in and out with the needs of the product applications—we needed the ability to migrate data across database shards in a client-transparent manner with zero downtime. This is a complex distributed systems problem, one that is further compounded by the unique requirements of important financial data:
为了构建一个水平可扩展且高度弹性的 DBaaS 服务——能够根据产品应用的需求进行扩展和缩减——我们需要具备在客户端透明的方式下迁移数据库分片数据,且无需停机的能力。这是一个复杂的分布式系统问题,而重要金融数据的独特需求进一步加剧了这一问题的复杂性:
To address these requirements, we built the Data Movement Platform to manage online data migrations across database shards by invoking purpose-built services.
为满足这些需求,我们构建了数据迁移平台,通过调用专门构建的服务来管理数据库分片的在线数据迁移。
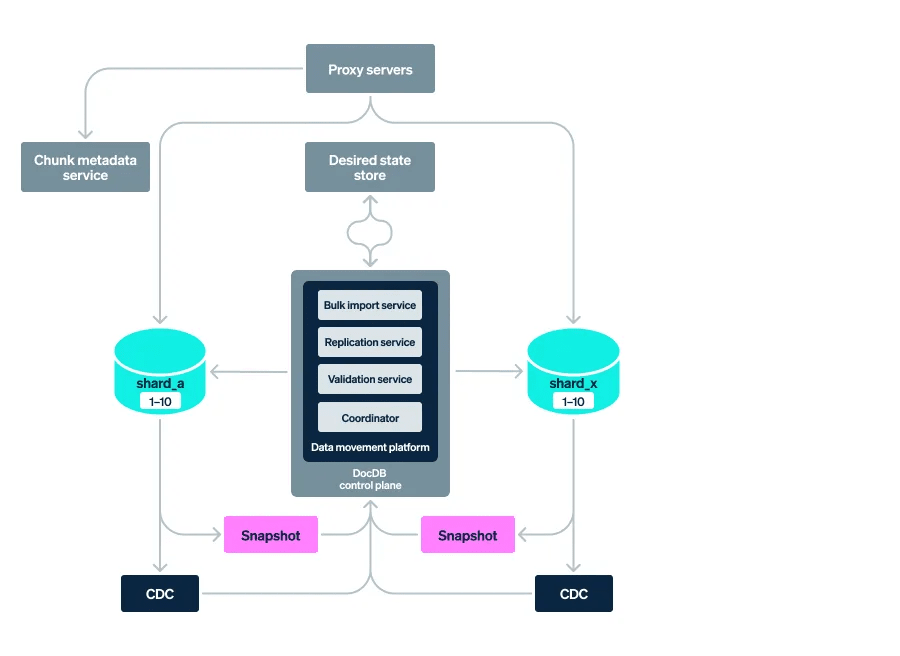 Data Movement Platform within our database infrastructure stack
Data Movement Platform within our database infrastructure stack
数据库基础设施堆栈中的数据迁移平台
The Coordinator component in the Data Movement Platform is responsible for orchestrating the various steps involved in online data migrations—it invokes the relevant services to accomplish each of the constituent steps outlined below:
数据迁移平台中的协调器组件负责编排在线数据迁移所涉及的各个步骤——它调用相关服务来完成下面列出的各个构成步骤:
First we register the intent to migrate database chunks from their source shards to arbitrary target shards in the chunk metadata service. Subsequently, we build indexes on the target shards for the chunks being migrated.
首先,我们在分片元数据服务中注册将数据库分片从源分片迁移到任意目标分片的意图。随后,我们为正在迁移的分片在目标分片上建立索引。
Next, we use a snapshot of the chunks on the source shards at a specific time, denoted as time T, to load the data onto one or more database shards. The service responsible for performing bulk data import accepts various data filters, and only imports the chunks of data that satisfy the filtering criteria. While this step appeared simple at first, we encountered throughput limitations when bulk loading data onto a DocDB shard. Despite attempts to address this by batching writes and adjusting DocDB engine parameters for optimal bulk data ingestion, we had little success.
接下来,我们使用源分片在特定时间点 T 的分片快照,将数据加载到一个或多个数据库分片上。负责执行批量数据导入的服务接受各种数据过滤器,并且仅导入满足过滤条件的数据分片。虽然这一步最初看起来很简单,但在将数据批量加载到 DocDB 分片时,我们遇到了吞吐量限制。尽管我们尝试通过批量写入和调整 DocDB 引擎参数以实现最佳批量数据摄取来解决这个问题,但收效甚微。
However, we achieved a significant breakthrough when we explored methods to optimize our insertion order, taking advantage of the fact that DocDB arranges its data using a B-tree data structure. By sorting the data based on the most common index attributes in the collections and inserting it in sorted order, we significantly enhanced the proximity of writes—boosting write throughput by 10x.
然而,当我们探索优化插入顺序的方法时,我们取得了重大突破,利用了 DocDB 使用 B 树数据结构组织数据的事实。通过根据集合中最常见的索引属性对数据进行排序,并按排序顺序插入,我们显著提高了写入的邻近性——将写入吞吐量提升了 10 倍。
Once we have imported the data onto the target shard, we begin replicating writes starting at time T from the source to the target shard for the database chunks being migrated. Our async replication systems read the mutations resulting from writes on the source shards from the CDC systems and issue writes to the target shards. 一旦我们将数据导入目标分片,我们就开始从时间 T 开始,对正在迁移的数据库块从源分片到目标分片进行写操作复制。我们的异步复制系统从 CDC 系统读取源分片上写操作产生的变更,并向目标分片发出写操作。
The operations log, or oplog, is a special collection on each DocDB shard that keeps a record of all the operations that mutate data in databases on that shard. We transport the oplog from every DocDB shard to Kafka, an event streaming platform, and then archive it to a cloud object storage service such as Amazon S3. (If you want to learn more about oplog, this is a helpful primer.)
操作日志,或 oplog,是每个 DocDB 分片上的一个特殊集合,用于记录所有在分片上数据库中修改数据操作。我们将 oplog 从每个 DocDB 分片传输到 Kafka(一个事件流平台),然后将其归档到云对象存储服务(如 Amazon S3)。(如果您想了解更多关于 oplog 的信息,这是一份有用的入门指南。)
We built a service to replicate mutations from one or more source DocDB shards to one or more target DocDB shards using the oplog events in Kafka and Amazon S3. We relied on the oplog events from our CDC systems to ensure that we didn’t slow user queries by consuming read throughput that would otherwise be available to user queries on the source shard, and to avoid being constrained by the size of the oplog on the source shard. We designed the service to be resilient to target shard unavailability, and to support starting, pausing, and resuming synchronization from a checkpoint at any point in time. The replication service also exposes the functionality to fetch the replication lag. 我们构建了一个服务,使用 Kafka 和 Amazon S3 中的 oplog 事件,将一个或多个源 DocDB 分片的变更复制到一个或多个目标 DocDB 分片。我们依赖 CDC 系统的 oplog 事件,以确保不会因消耗本应用于源分片用户查询的读取吞吐量而减慢用户查询速度,并避免受限于源分片 oplog 的大小。我们设计了该服务,使其能够适应目标分片不可用的情况,并支持从任意时间点的检查点开始、暂停和恢复同步。复制服务还提供了获取复制延迟的功能。
Mutations of the chunks under migration get replicated bidirectionally—from the source shards to the target shards and vice versa—and the replication service tags the writes it issues to avert cyclical asynchronous replication. We made this design choice to provide the flexibility to revert traffic to the source shards if any issues emerge when directing traffic to the target shards.
迁移中的数据块发生双向复制——从源分片到目标分片,以及反向复制——复制服务会标记其发出的写入操作,以避免循环异步复制。我们做出这种设计选择是为了在将流量导向目标分片时出现任何问题时,能够灵活地将流量恢复到源分片。
After the replication syncs between the source and target shard, we conduct a comprehensive check for data completeness and correctness by comparing point-in-time snapshots—a deliberate design choice we made in order to avoid impacting shard throughput.
在源分片和目标分片之间的复制同步完成后,我们通过比较即时快照进行全面的数据完整性和正确性检查——这是我们有意识做出的设计选择,以避免影响分片吞吐量。
Once the data in a chunk is imported from the source to the target shard—and mutations are actively replicated—a traffic switch is orchestrated by the Coordinator. In order to reroute reads and writes to the chunk of data being migrated, we need to first: stop the traffic on the source shard for a brief period of time, update the routes in the chunk metadata service, and have the proxy servers redirect reads and writes to the target shards. 一旦数据块中的数据从源导入目标分片,并且变更被积极复制——协调器就会编排流量切换。为了将读和写重新路由到正在迁移的数据块,我们需要首先:暂停源分片上的流量一小段时间,更新块元数据服务中的路由信息,并让代理服务器将读和写重定向到目标分片。
The traffic switch protocol is based on the idea of versioned gating. In steady state, each proxy server annotates requests to DocDB shards with a version token number. We added a custom patch to MongoDB that allows a shard to enforce that the version token number it receives on requests from the proxy servers is newer than the version token number it knows of—and only serve requests that satisfy this criterion. To update the route for a chunk, we use the Coordinator to execute the following steps:
流量切换协议基于版本化门控的概念。在稳定状态下,每个代理服务器都会为 DocDB 分片的请求添加版本令牌编号。我们为 MongoDB 添加了一个自定义补丁,允许分片强制执行从代理服务器收到的版本令牌编号必须比它所知的版本令牌编号更新——并且只服务满足此标准的请求。为了更新数据块的路线,我们使用协调器执行以下步骤:
 Traffic switch process 流量切换过程
Traffic switch process 流量切换过程
Upon completion, the proxy servers fetch the updated routes for the chunk and the most up-to-date version token number from the chunk metadata service. Using the updated routes for the chunk, the proxy servers route reads and writes for the chunk to the target shard. The entire traffic switch protocol takes less than two seconds to execute, and all failed reads and writes directed to the source shard succeed on retries. 完成时,代理服务器从数据块元数据服务中获取数据块的更新路由和最新版本令牌号。使用数据块的更新路由,代理服务器将数据块的读写流量路由到目标分片。整个流量切换协议执行时间不到两秒,所有重试后指向源分片的失败读写操作均成功。
Finally, we conclude the migration process by marking the migration as complete in the chunk metadata service and subsequently dropping the chunk data from the source shard.
最后,我们通过在块元数据服务中标记迁移为完成来结束迁移过程,并随后从源分片中删除块数据。
The ability to migrate chunks of data across DocDB shards in an online manner helps us horizontally scale our database infrastructure to keep pace with the growth of Stripe. Engineers on the database infrastructure team are able to split DocDB shards for size and throughput with a click of a button, freeing up database storage and throughput headroom for product teams. 能够在 DocDB 分片中以在线方式迁移数据块的能力,帮助我们水平扩展数据库基础设施,以跟上 Stripe 的增长。数据库基础设施团队的工程师能够通过单击按钮来拆分 DocDB 分片,从而为产品团队释放数据库存储和吞吐量空间。
In 2023, we used the Data Movement Platform to improve the utilization of our database infrastructure. Concretely, we bin-packed thousands of underutilized databases by migrating 1.5 petabytes of data transparent to product applications, and reduced the total number of underlying DocDB shards by approximately three quarters. We also used the Data Movement Platform to upgrade our database infrastructure fleet by fork-lifting data to a later version of MongoDB in one step—without going through intermediate major and minor versions with an in-place upgrade strategy. 2023 年,我们使用数据迁移平台提高了数据库基础设施的利用率。具体来说,我们通过迁移 1.5PB 的数据(对产品应用透明),将数千个利用率不足的数据库进行了紧凑打包,并将底层 DocDB 分片总数减少了约四分之三。我们还使用数据迁移平台通过一次性将数据迁移到 MongoDB 的更高版本来升级我们的数据库基础设施舰队——无需通过就地升级策略经历中间的主要和次要版本。
The database infrastructure team at Stripe is focused on building a robust and reliable foundation that scales with the growth of the internet economy. We are currently prototyping a heat management system that proactively balances data across shards based on size and throughput, and investing in shard autoscaling that dynamically responds to changes in traffic patterns. Stripe 的数据库基础设施团队致力于构建一个能够随着互联网经济的增长而扩展的稳健可靠的基础设施。我们目前正在原型设计一个热量管理系统,该系统根据数据大小和吞吐量主动平衡分片中的数据,并投资于分片自动扩展,以动态响应流量模式的变化。