15445-06-StorageModelCompression
发布于 • 作者: Ethan
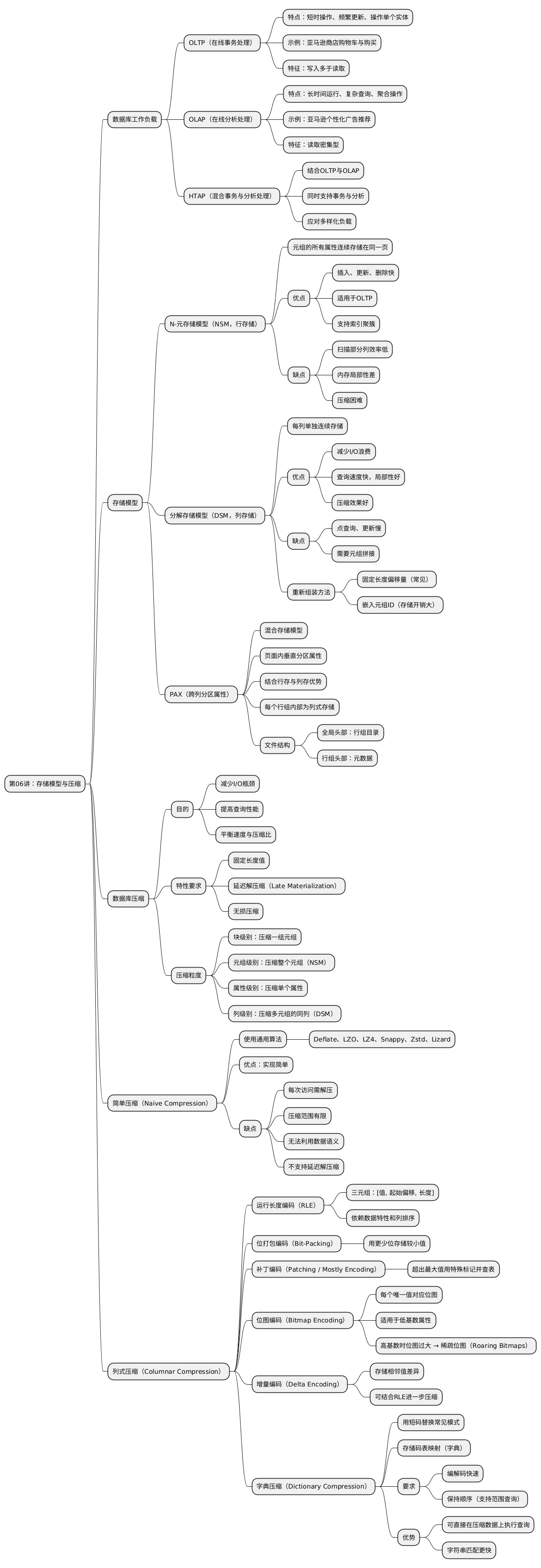
OLTP 工作负载的特点是快速、短时运行的操作、重复性操作,以及每次仅对单个实体进行简单查询。
OLTP 工作负载通常写入操作多于读取操作,并且每次仅读取或更新少量数据。
例子: 亚马逊商店。用户可以将商品加入购物车并进行购买,但这些操作只影响他们的账户。
OLAP 工作负载的特点是长时间运行、复杂的查询(通常涉及计算聚合)以及对数据库大范围数据的读取。
在 OLAP 工作负载中,数据库系统通常分析并从 OLTP 侧收集的现有数据中推导出新的数据。
例子: 个性化的亚马逊购物广告,网站分析用户购物车和购买行为的数据,为不同用户选择不同广告。
HTAP 是一种新型的工作负载,其中 OLTP 和 OLAP 工作负载共存于同一数据库实例中。
工作负载重点:
数据库系统中,元组(tuple)在页面中的存储方式不同。
在 n-元存储模型中,DBMS 将单个元组的所有属性连续地存储在同一页面中。
这种方式非常适合 OLTP 工作负载。
优点:
缺点:
在 DSM 中,DBMS 将每个属性(列)分别连续存储在数据块中。
适合 OLAP 工作负载。
优点:
缺点:
重建元组的两种方式:
混合型存储模型,DBMS 在页面内部垂直划分属性。
结合行存储的空间局部性与列存储的高效扫描。
结构:
压缩常用于基于磁盘的 DBMS,以缓解磁盘 I/O 瓶颈。
在只读分析型系统中尤为常见。压缩能减少 I/O 但增加 CPU 计算开销。
对于内存数据库,需要在速度与压缩比之间平衡。
压缩方案应具备的特性:
使用通用压缩算法(如 Deflate、LZO、LZ4、Snappy、Zstd 等)。
通常以牺牲压缩率换取更高的压缩/解压速度。
缺点:
列式压缩方案允许 DBMS 在不解压为原始形式的情况下读取数据。
压缩相同值的连续段,存储三元组:
RLE 效果取决于数据特性及列排序。
当值小于最大声明大小时,用更少位存储。
为超出最大值的项使用特殊标记,并维护查找表。
为每个唯一值存储一个位图,位图中的位置对应表中元组是否包含该值。
适用于低基数属性(低唯一值数量)。
当基数过高时,位图会变大,可采用稀疏结构(如 Roaring Bitmaps)。
记录相邻值之间的差异,可结合 RLE 进一步压缩。
最常见的数据库压缩方案。
DBMS 使用较短的代码替换常见值,并维护映射表(字典)。
要求:
保持顺序的编码允许直接在压缩数据上执行操作,提高查询性能(如字符串匹配)。

