mindmap
一、缓冲池优化(Buffer Pool Optimizations)
有几种方法可以优化缓冲池,使其更好地适应应用程序的工作负载。
多个缓冲池(Multiple Buffer Pools)
数据库管理系统(DBMS)可以维护多个缓冲池,用于不同的目的(例如按数据库、按表、按页类型等)。
每个缓冲池都可以采用针对其内部存储数据的本地策略,从而减少锁竞争并提高局部性。
将目标页映射到缓冲池的常见方法包括:
- 对象 ID(Object IDs):将记录 ID 扩展以包含对象标识符,并维护对象到缓冲池的映射。这允许更细粒度的内存管理,但增加了存储开销。
- 哈希(Hashing):将页 ID 进行哈希以决定使用哪个缓冲池。这种方式更通用且分布均匀。
预取(Pre-fetching)
DBMS 可以根据查询计划预取数据页。
当第一批页正在处理时,第二批页可以预先加载到缓冲池中。
典型应用场景包括:
- 顺序扫描(Sequential Scan):访问大量连续页时使用。
- 索引扫描(Index Scan):预取树索引的叶节点页,以减少访问延迟。
注意:预取的页不一定是磁盘上的物理连续页,而是逻辑上相邻的页。
扫描共享(Scan Sharing / Synchronized Scans)
多个查询可以共享同一个扫描游标,从而重用已经从存储中检索到的数据。
当一个新的扫描启动时,如果另一个扫描正在运行,DBMS 会让新查询的游标附加到现有游标上。
系统会记录两个查询的连接点,以确保结果正确。
由于扫描顺序在多数情况下并无保证,因此这种机制非常实用,尤其在表被频繁扫描时。
注意: 连续扫描共享是一种学术原型,系统会持续扫描特定表,查询可以随时加入或退出。
但这种方式在按 I/O 计费的场景下非常浪费。
总结:
DBMS 通常比操作系统更擅长管理内存,因为它能利用查询计划的语义信息进行更优决策:
- 页面驱逐(Evictions)
- 页面分配(Allocations)
- 页面预取(Pre-fetching)
再说一遍:操作系统不是你的朋友。
二、元组导向存储(Tuple-Oriented Storage)
最常见的存储方式是元组导向存储架构(Tuple-Oriented Storage),通常使用槽页结构(Slotted Page)。
元组读取步骤
- 检查页目录,找到对应磁盘页位置。
- 将页从磁盘载入内存(缓冲池)。
- 通过槽数组找到元组在页中的偏移量。
元组插入步骤
- 查找页目录,定位一个有空闲槽的页。
- 加载该页到内存。
- 检查是否有足够空间。
- 若无,创建新页或寻找另一个页。
- 插入元组并更新槽数组。
元组更新步骤
- 通过记录 ID 定位元组。
- 若新值可放入原位置,则就地更新。
- 否则,标记旧元组为删除,并插入新元组。
存在的问题
- 碎片化(Fragmentation):删除元组后页内空间浪费。
- 无用磁盘 I/O(Useless Disk I/O):块级存储导致更新单个元组也要读取整块。
- 随机磁盘 I/O(Random I/O):更新多个分散的元组会很慢。
在某些系统(如 HDFS、Google Colossus)中,不支持就地更新,只能追加写入。这种场景可采用日志结构化存储模型(Log-Structured Storage)。
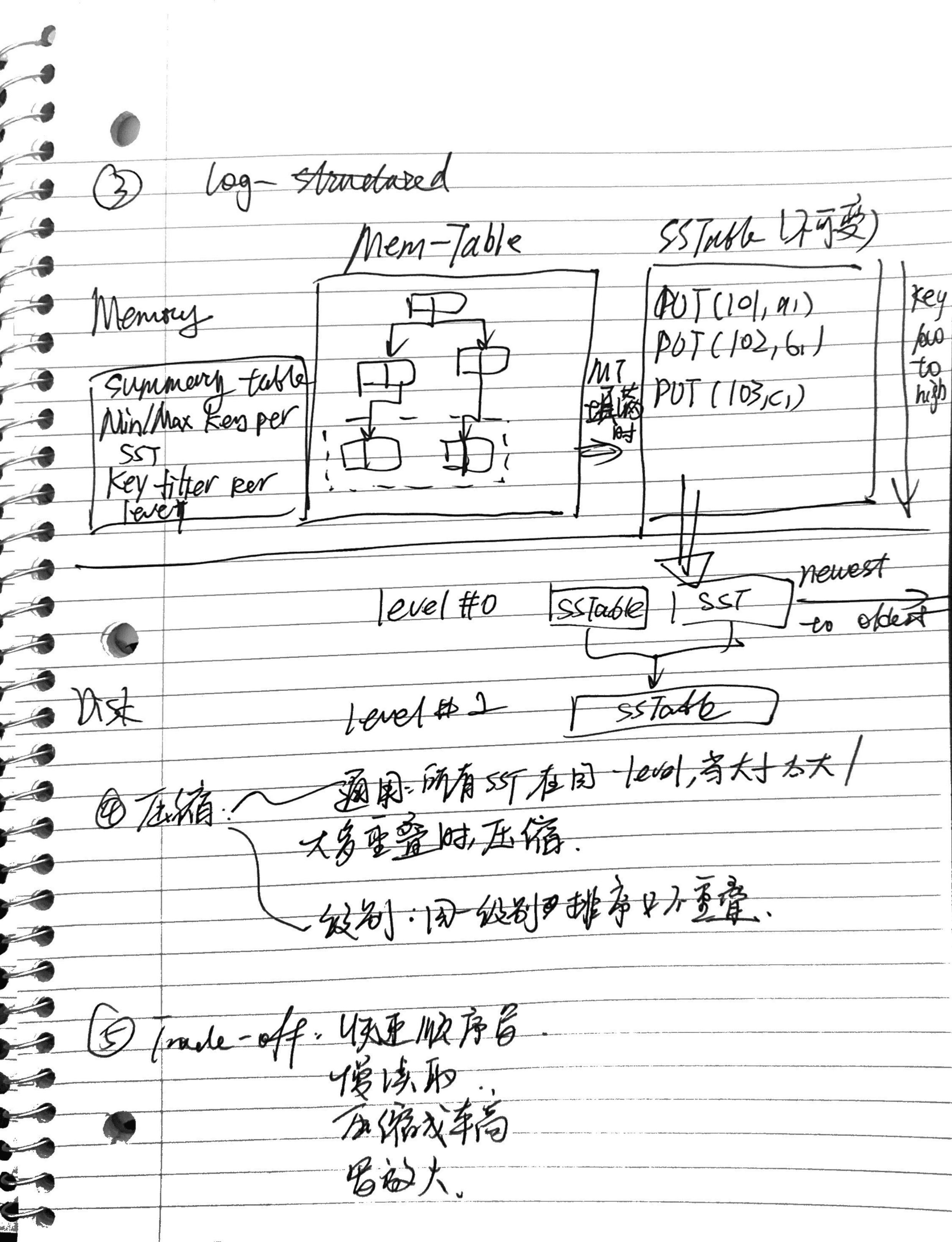
三、日志结构化存储(Log-Structured Storage)
日志结构化存储(LSS)不直接在页内更新元组,而是维护记录变更的日志。
此思想源自:
- Log-Structured File System (LSFS)
- Log-Structured Merge Tree (LSM Tree)
基本机制
- 所有更新首先写入内存结构 MemTable。
- 当 MemTable 满时,DBMS 将内容序列化写入磁盘形成 SSTable。
- SSTable 按键排序并顺序写入磁盘。
- 每条记录包括:
- 唯一标识符(Key)
- 操作类型(PUT / DELETE)
- 内容(仅 PUT 时包含)
这种方式可显著减少随机 I/O,非常适合仅追加存储系统。
读取流程
- 先查询 MemTable。
- 若不存在,再从最新到最旧逐层扫描 SSTables(通常结合布隆过滤器或摘要表)。
为了加速读取,DBMS 维护:
- SummaryTable:记录每个 SSTable 的最小/最大键。
- Bloom Filter:快速判断键是否可能存在于某层。
压缩(Compaction)
在写密集型负载下,磁盘上会积累大量 SSTables。
DBMS 会周期性地使用**排序合并算法(Sort-Merge)**压缩文件,只保留每个键的最新版本。
压缩策略:
- 通用压缩(Universal Compaction):所有 SSTables 位于一个通用层。
- 分层压缩(Level Compaction):文件分层管理(Level 0、Level 1、Level 2 …),较小文件逐层合并。
权衡(Tradeoffs)
| 优势 |
劣势 |
| 快速顺序写入,适合仅追加存储 |
读取速度较慢 |
|
压缩操作开销大 |
|
写入放大效应(多个物理写对应一个逻辑写) |
四、索引组织存储(Index-Organized Storage)
槽页存储与日志结构化存储都依赖外部索引来定位元组,因为表本身是无序的。
在索引组织存储中,DBMS 直接将表的元组存储为索引结构的值(如 B+ 树、跳表、Trie 等)。
页面布局类似于槽页(slotted page),
并且元组通常按键值排序存储,以支持高效的范围查询与更新。
Notes