Mindmap
一、概述(Overview)
SQL 是一种声明式语言,查询仅指定 要计算什么,而非 如何计算。因此,数据库管理系统(DBMS)需要将 SQL 语句转换为可执行的查询计划(Query Plan)。
- 查询计划中的每个操作符(如连接、筛选等)都有多种执行方式。
- 不同执行计划在性能上差异巨大。
- 优化器(Optimizer)的任务是:为每个查询选择最优执行计划。
历史背景:
第一个查询优化器由 IBM System R 项目在 1970 年代设计。
该系统证明 DBMS 能比人类更好地生成查询计划。
System R 优化器的思想至今仍被广泛使用。
尽管近年来有系统尝试使用机器学习改进优化器的性能与准确性,但尚无主流 DBMS 真正部署基于机器学习的优化器。
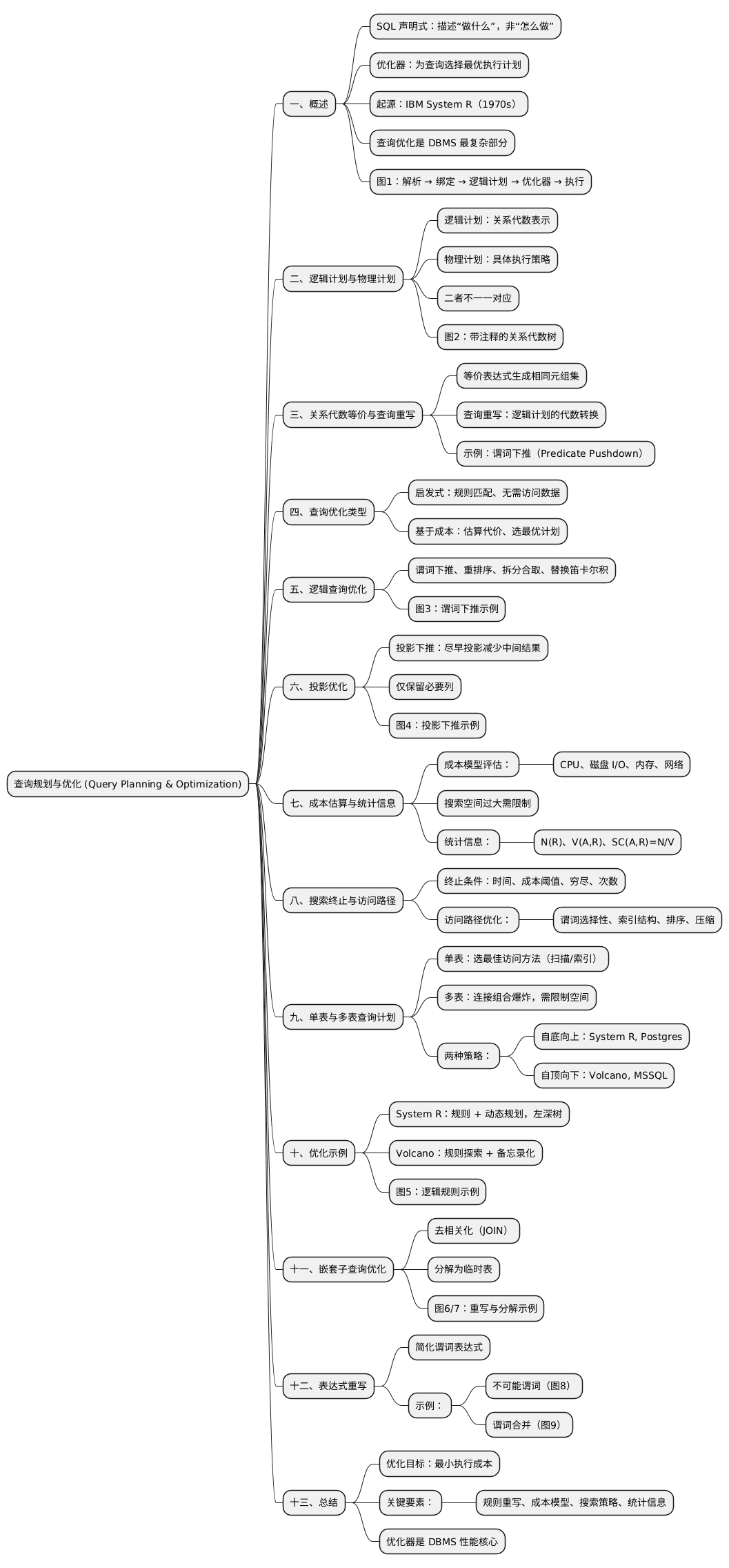
图 1:架构概述(Architecture Overview)
应用程序连接数据库并发送 SQL 查询:
- SQL 查询可被重写(Query Rewriting)。
- SQL 字符串被解析(Parsing)为语法树。
- 绑定器(Binder)通过系统目录(Catalog)将命名对象映射为内部标识符。
- 绑定器生成逻辑计划(Logical Plan),供树重写器(Tree Rewriter)进一步处理。
- 优化器(Optimizer)根据逻辑计划选择最优物理执行计划。
二、逻辑计划与物理计划(Logical vs. Physical Plans)
优化器的核心任务:
将逻辑代数表达式映射到最优的物理代数表达式。
- 逻辑计划(Logical Plan):表示查询的关系代数表达式。
- 物理计划(Physical Plan):指定实际执行方式,包括访问路径与数据结构。
注意:逻辑与物理计划之间不一定一一对应。
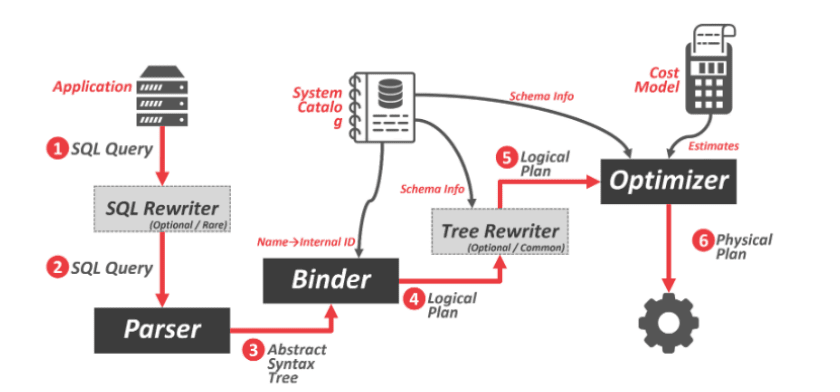
图 2:物理计划的关系代数树
 可视为带有实现注释的关系代数树,包含执行所需的物理信息。
可视为带有实现注释的关系代数树,包含执行所需的物理信息。
三、关系代数等价(Relational Algebra Equivalence)
查询优化基于关系代数的等价变换原理:
若两个关系代数表达式生成的元组集合相同,则它们是等价的。
这种基于代数表达式变换的优化称为 查询重写(Query Rewriting)。
示例:谓词下推(Predicate Pushdown)
将谓词在不同阶段应用,以减少不必要的计算。
四、查询优化的类型(Types of Query Optimization)
查询优化策略主要分为两大类:
(一)启发式(Heuristic / Rule-based)
- 使用静态规则匹配已知模式。
- 通过重写消除低效操作。
- 规则依赖目录信息(Catalog),但不访问真实数据。
(二)基于成本(Cost-based)
- 通过访问统计信息估计不同执行计划的代价。
- 使用成本模型选择代价最低的执行计划。
五、逻辑查询优化(Logical Query Optimization)
通过规则匹配,将逻辑计划转换为更高效但等价的逻辑计划。
常见优化类型
- 谓词下推(Predicate Pushdown):尽早执行过滤操作。
- 谓词重排序(Predicate Reordering):先执行选择性最高的谓词。
- 合取谓词拆分(Conjunctive Predicate Splitting):拆分复杂谓词并下推。
- 笛卡尔积替换(Replace Cartesian Product):将笛卡尔积转为内连接。
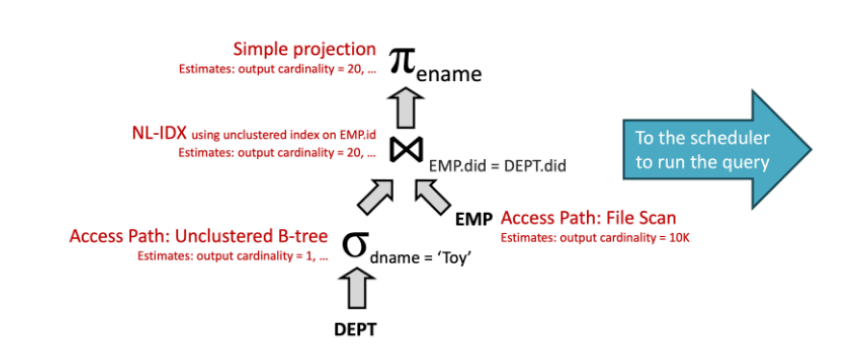
图 3:谓词下推示例
将过滤器提前执行,以减少后续连接中需处理的数据量。
六、投影优化(Projection Optimization)
常见方法
- 投影下推(Projection Pushdown):尽早执行投影,减少中间元组大小。
- 仅保留必要列,去除无关字段。
- 投影优化效果取决于列数与元组宽度。
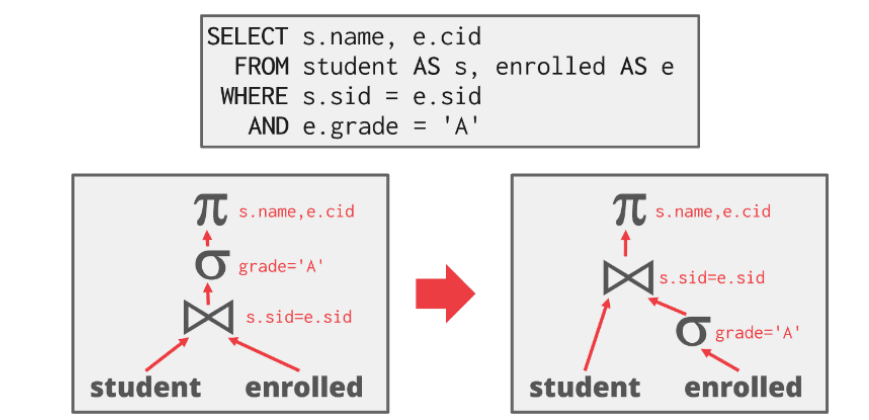
图 4:投影下推示例
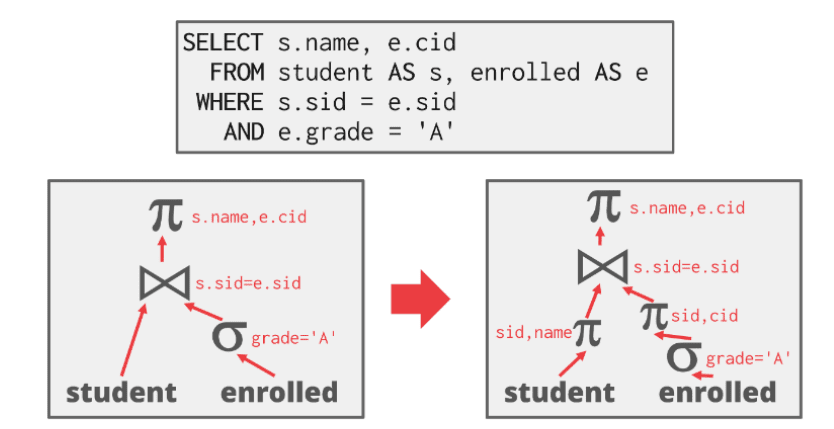 查询仅请求学生姓名与 ID,系统可在连接前移除其他列。
查询仅请求学生姓名与 ID,系统可在连接前移除其他列。
七、基于成本的查询优化(Cost-Based Query Optimization)
- DBMS 先进行基于规则的重写。
- 然后枚举可能的物理计划并估算其成本。
- 选择代价最低的计划(或在超时前的最佳计划)。
八、成本估算(Cost Estimation)
DBMS 使用 成本模型 来评估查询计划执行的代价。
关键指标
- CPU 成本(难以准确估算)
- 磁盘 I/O(块传输次数)
- 内存占用
- 网络传输(消息数量)
由于枚举所有计划过于耗时,优化器通常限制搜索空间。
对于 n 个连接,存在约 4ⁿ 种不同的连接顺序。
内部统计信息
DBMS 在系统目录中维护:
- 表、属性、索引的统计信息;
- 统计数据通常异步更新;
- 避免运行时即刻计算。
九、统计信息与选择基数(Selectivity & Statistics)
对于每个关系 R,DBMS 维护:
- N(R):关系 R 中的元组数量
- V(A, R):属性 A 的不同值数量
由此可计算:
选择基数(Selection Cardinality):
SC(A, R) = N(R) / V(A, R)
此计算假设数据分布均匀,虽然现实中并非如此,但简化了优化过程。
十、搜索终止条件(Search Termination)
优化器在探索计划时需判断何时停止:
- (一)时间限制:运行超过固定时长即停。
- (二)成本阈值:找到低于阈值的计划后停止。
- (三)穷尽搜索:无更多计划可枚举时终止。
- (四)规则次数限制:应用规则次数达到上限时停止。
优化器需选择最小化数据访问成本的路径,并可调整谓词顺序。
影响因素
- 谓词选择性(Selectivity)
- 数据结构(如 B+ 树 vs. 哈希索引)
- 表或索引排序顺序
- 数据特征(如 INCLUDE、Zone Map)
- 压缩与编码策略
十二、单关系查询计划(Single-Relation Query Plans)
主要任务:选择最优访问方法(顺序扫描、索引扫描、二分搜索等)。
多数现代数据库使用启发式方法而非复杂成本模型。
对于 OLTP 查询:
- 通常具备可搜索性(Sargable)。
- DBMS 可选出最合适的索引。
十三、多关系查询计划(Multi-Relation Query Plans)
随着连接数量增加,计划组合数迅速膨胀。
为在合理时间内找到最优计划,必须限制搜索空间。
两种主流策略
-
生成式 / 自底向上(Generative / Bottom-Up)
- 从空计划逐步构建目标。
- 代表系统:IBM System R、DB2、MySQL、Postgres 等。
-
转换式 / 自顶向下(Transformational / Top-Down)
- 从目标结果出发,逐层分解寻找最优子计划。
- 代表系统:MSSQL、Greenplum、CockroachDB。
十四、自底向上优化示例:System R
使用静态规则进行初步优化,然后利用**动态规划(Dynamic Programming)**确定最优连接顺序。
步骤:
- 将查询分解为多个块(Blocks)。
- 为每个逻辑操作符生成对应的物理实现。
- 构造左深树(Left-Deep Tree),以最小化执行代价。
十五、自顶向下优化示例:Volcano
Volcano 优化器从初始逻辑计划开始,
通过规则递归探索逻辑与物理转换空间。
-
规则分为两类:
- 逻辑到逻辑(Transformation Rules)
- 逻辑到物理(Implementation Rules)
特点
- 使用**备忘录化(Memoization)**避免重复探索。
- 在搜索过程中记录全局最优计划。
- 将数据的物理属性视为规划的一等要素。
图 5:示例逻辑规则
 系统规则集定义了优化器的搜索空间。
系统规则集定义了优化器的搜索空间。
十六、嵌套子查询优化(Nested Subquery Optimization)
DBMS 将 WHERE 子句中的嵌套查询视为函数(带参数返回值)。
优化方法:
-
去相关化 / 展平(De-correlation / Flattening)
- 将子查询改写为 JOIN。
- 如图 6 所示,移除嵌套层级。
-
分解(Decomposition)
- 将嵌套查询结果存储于临时表。
- 如图 7 所示,对嵌套聚合查询特别有效。
十七、表达式重写(Expression Rewriting)
优化器会将查询中的布尔表达式或谓词转化为最简形式。
过程
- 搜索匹配特定模式的表达式;
- 找到匹配后进行重写;
- 若无可应用规则则终止。
示例
- 不可能谓词(Impossible Predicate):
在优化阶段提前评估无效表达式(图 8)。
- 谓词合并(Merging Predicate):
例如
WHERE a > 1 AND a < 150 可简化为区间表达式(图 9)。
总结
查询优化是数据库系统中最具挑战性的部分。
其目标是:在有限时间内找到代价最小的可行计划。
优化器综合使用:
- 逻辑规则(规则重写)
- 成本模型(代价评估)
- 搜索策略(自底向上 / 自顶向下)
- 统计信息(数据分布、选择性)
最终实现 高效、自动化的 SQL 执行优化。