15445-08-IndexesFilters(I)
发布于 • 作者: Ethan
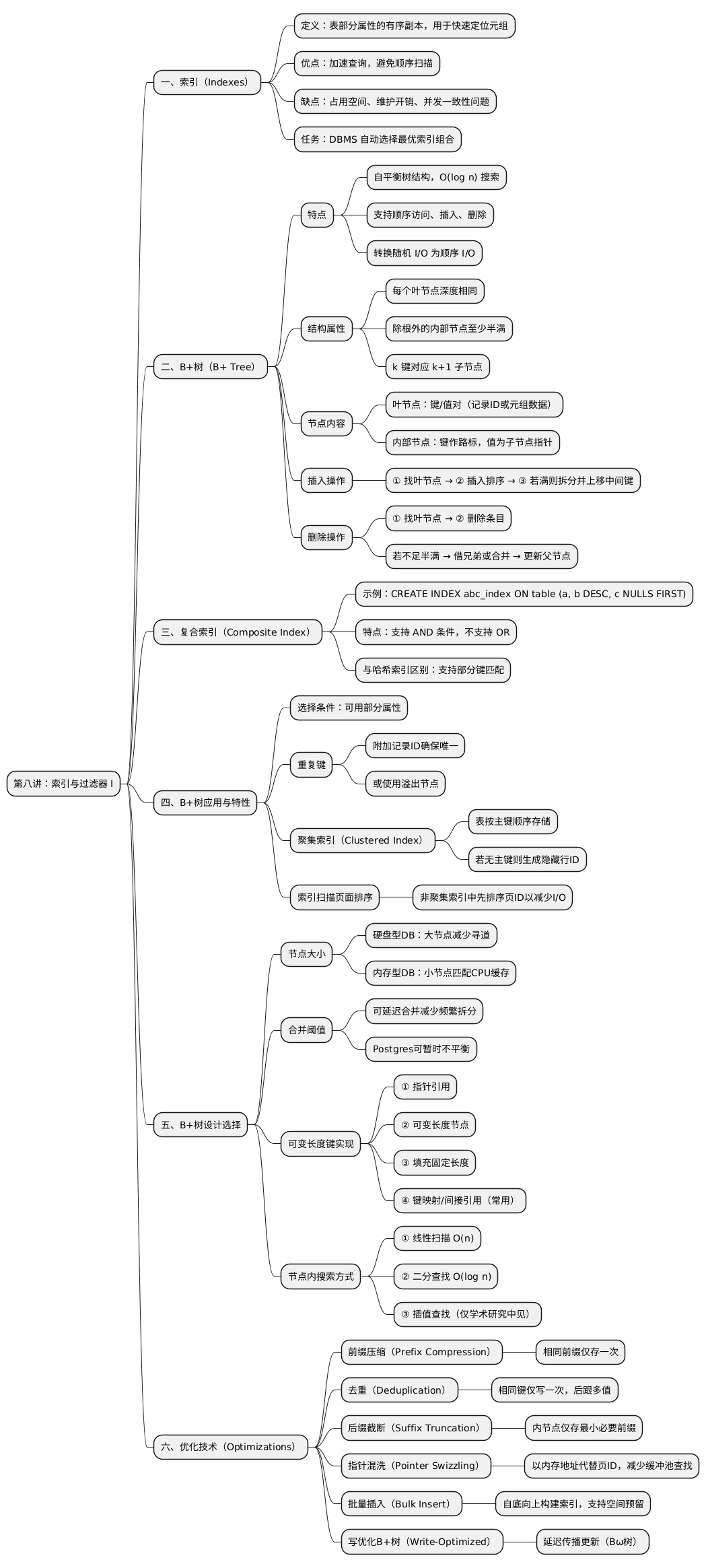
数据库管理系统(DBMS)中存在多种数据结构,应用于内部元数据、核心数据存储、临时结构或索引等目的。 本讲主要关注索引。
索引是表中部分属性的副本,通过组织和排序实现高效的数据定位。相比顺序扫描,DBMS 可以通过索引快速定位目标元组。
然而,索引数量存在权衡:
DBMS 的任务是选择最优索引组合以加速查询。
B+树是一种自平衡树结构,支持排序、搜索、顺序访问、插入与删除,时间复杂度为 O(log n)。 它针对磁盘数据库优化,将潜在的随机 I/O 转换为顺序 I/O。
几乎所有现代支持有序索引的 DBMS 都采用 B+树。
B+树是一个 m 路搜索树(m 为扇出):
节点内部通常保存键/值对数组。
找到正确叶节点 L;
将新条目插入并保持排序:
若内部节点也需拆分,重复上述过程。
找到正确叶节点 L;
删除对应条目:
若发生合并,需删除父节点中对应指针。
索引键可由多个属性组成:
CREATE INDEX abc_index ON table (a, b DESC, c NULLS FIRST);
查询示例:
SELECT a, b, c FROM table
WHERE a = 1 AND b = 2 AND c = 3;
注意:B+树索引通常仅支持
AND条件,不支持OR。
B+树按键排序,可高效支持部分键匹配。 与哈希索引不同,B+树不要求匹配所有搜索键属性。
处理重复键的两种方式:
表数据按主键排序存储,可为堆组织或索引组织。 部分 DBMS 若无显式主键,会自动生成隐藏行 ID。
对于非聚集索引,DBMS 可先获取所有目标元组并按页 ID 排序,以减少页面读取次数。
选择取决于工作负载类型:
删除操作时可延迟合并,以减少频繁的分裂与合并。 部分系统(如 PostgreSQL)允许暂时不平衡的树结构。
实现方式包括:
若同一节点的键共享相同前缀,只需存储一次前缀,提高空间利用率。
对于非唯一索引,可仅存储一次键,后接多个值。
内部节点仅需保存最小前缀即可正确引导查询路径。
用内存地址替代页 ID,避免缓冲池查找开销; 当页被释放时需恢复原 ID。
初次建树时,可先构造排序好的叶节点链表,再自底向上建立索引。 可选择紧密存储或预留空间以便后续插入。
分裂与合并代价高,某些变体(如 Bω树)采用延迟传播方式: 先记录内部节点的更新日志,再异步写入叶节点。



