15445-14-QueryExecution(II)
发布于 • 作者: Ethan
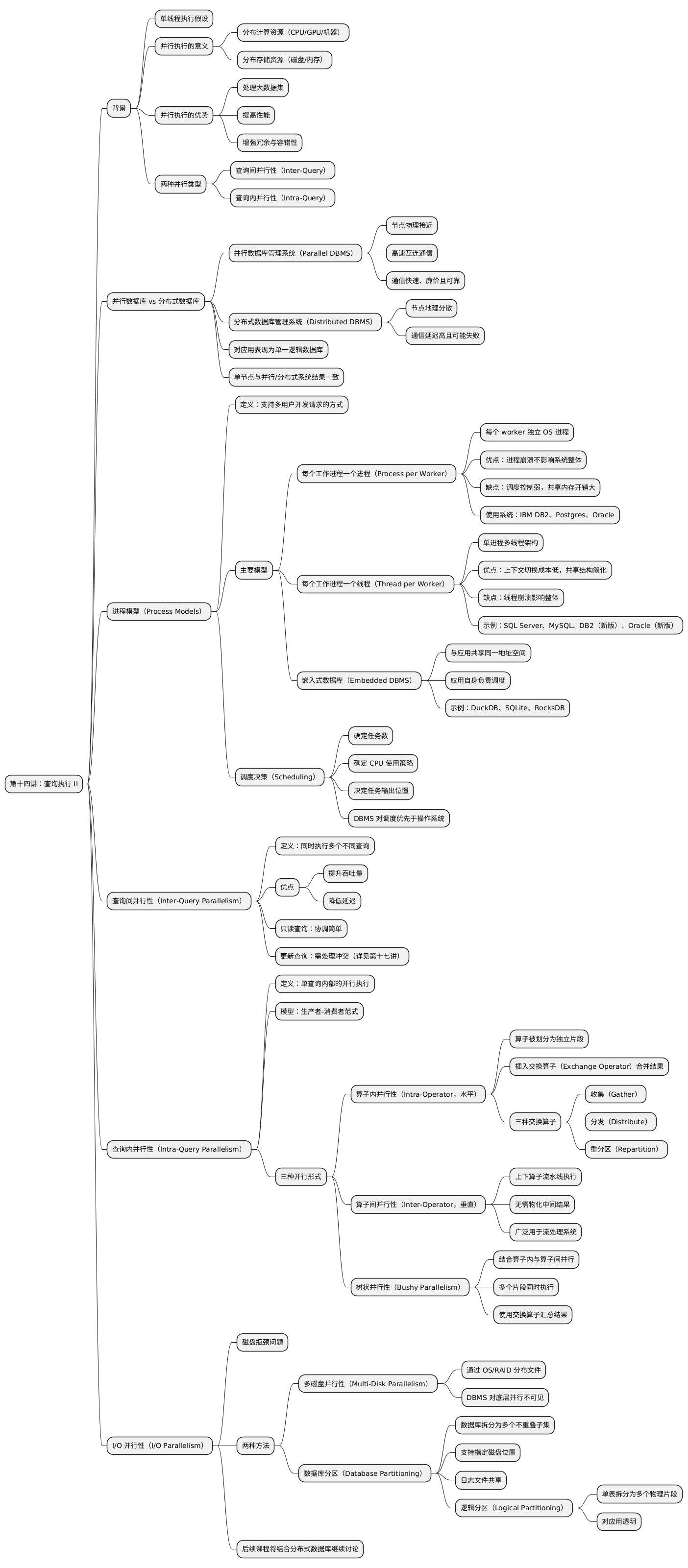
在此前的讨论中,查询执行假设仅由单个工作线程执行。然而在实际系统中,查询通常以并行方式由多个工作线程协同执行。
并行执行会将数据库分布到多个资源上,这些资源可能包括:
分布到多个资源上的数据库具备以下优点:
数据库管理系统(DBMS)通常支持两类并行性:
需要明确区分两者的概念:
并行数据库管理系统(Parallel DBMS) 资源或节点物理上彼此靠近,通过高速互连通信。通信被认为快速、低成本且可靠。
分布式数据库管理系统(Distributed DBMS) 资源可能分布在全球不同机房或数据中心。通信通常通过较慢的公共网络完成,因此通信成本高,且必须考虑节点故障。
尽管数据库在物理上分布在多个资源上,但对应用程序而言,它仍表现为单一逻辑数据库实例。 因此,在单节点 DBMS 上执行的 SQL 查询,应当在并行或分布式 DBMS 上产生相同的结果。
DBMS 的进程模型定义了系统如何支持来自多个用户的并发请求。系统由一个或多个**工作单元(Worker)**组成,这些工作单元代表客户端执行任务并返回结果。
应用程序可能发送一个大型请求或多个请求,这些请求会分配到不同的工作单元。
主要的两种模型为:
此外,还有一种常见的嵌入式数据库模式(Embedded DBMS)。
在此模型中,每个工作单元是一个独立的操作系统进程,依赖操作系统调度。应用程序发送请求并与数据库建立连接。调度器接收请求后,会选择某个工作进程来处理连接,随后应用程序直接与该进程通信。
优缺点分析:
优点:
缺点:
为优化内存使用,可通过 共享内存(Shared Memory) 共享全局结构。
采用该模型的系统包括:IBM DB2、Postgres、Oracle。 当这些系统开发时,pthread 尚未成为标准线程模型,而
fork()定义更为明确。
在现代 DBMS 中最常见。系统仅有一个进程,但内部包含多个工作线程。DBMS 能完全控制调度和线程管理。
优势:
劣势:
该模型被广泛应用于 Microsoft SQL Server、MySQL 等现代 DBMS; IBM DB2、Oracle 也已更新以支持该模型; Postgres 及其衍生系统仍主要使用进程模型。
嵌入式模式下,数据库运行在应用程序的同一地址空间中,不再采用传统的客户端-服务器架构。 应用程序自身负责线程与任务调度。
典型系统包括:
在执行查询计划时,DBMS 需要决定:
相较操作系统,DBMS 对查询计划有更丰富的信息,因此在调度决策上应具有优先权。
查询间并行性指 DBMS 同时执行多个不同查询。 多个工作单元并行处理请求,从而:
若查询均为只读操作,协调较少; 若多查询同时修改数据,则可能产生复杂冲突(将在第十七讲讨论)。
查询内并行性指 DBMS 在单个查询内部并行执行操作。 这种方式显著减少长查询的延迟。
这一模式通常可理解为生产者/消费者模型(Producer–Consumer Paradigm): 每个操作符既消费下层算子输出的数据,又向上层算子生产数据。
查询计划中的算子被分解为多个独立片段,这些片段在不同数据子集上执行相同功能。 DBMS 会在查询计划中插入 交换算子(Exchange Operator) 以汇聚子算子结果。
交换算子确保上层算子在接收所有子算子输出前不会执行。
三类交换算子:
算子间并行性通过流水线执行(Pipeline Execution)将上、下层算子重叠运行,无需物化中间结果。 这种方式也称为管道并行(Pipelined Parallelism)。
广泛用于流处理系统(Stream Processing Systems),用于持续处理输入元组流。
树状并行性结合了算子内与算子间并行。 多个工作线程同时执行来自不同查询计划片段的操作。 DBMS 仍使用交换算子组合中间结果。
仅增加线程或进程并行执行查询,并不能缓解磁盘瓶颈。 因此,DBMS 需要将数据分布至多个存储设备。
I/O 并行性主要有两种方式:
在此模式下,操作系统或硬件层负责将数据库文件分布到多个设备上(如 RAID)。 DBMS 对底层分布不可见,无法直接利用磁盘级并行。
数据库可被划分为互不重叠的子集,并分别存储到不同磁盘。 部分 DBMS 支持用户指定每个数据库文件所在磁盘路径。
逻辑分区(Logical Partitioning): 将单个逻辑表划分为多个物理片段,每个片段独立存储与管理。 理想情况下,这对应用层是透明的——应用访问逻辑表时无需关心底层分布。
分布式数据库部分将在学期后期详细讨论。