Mindmap
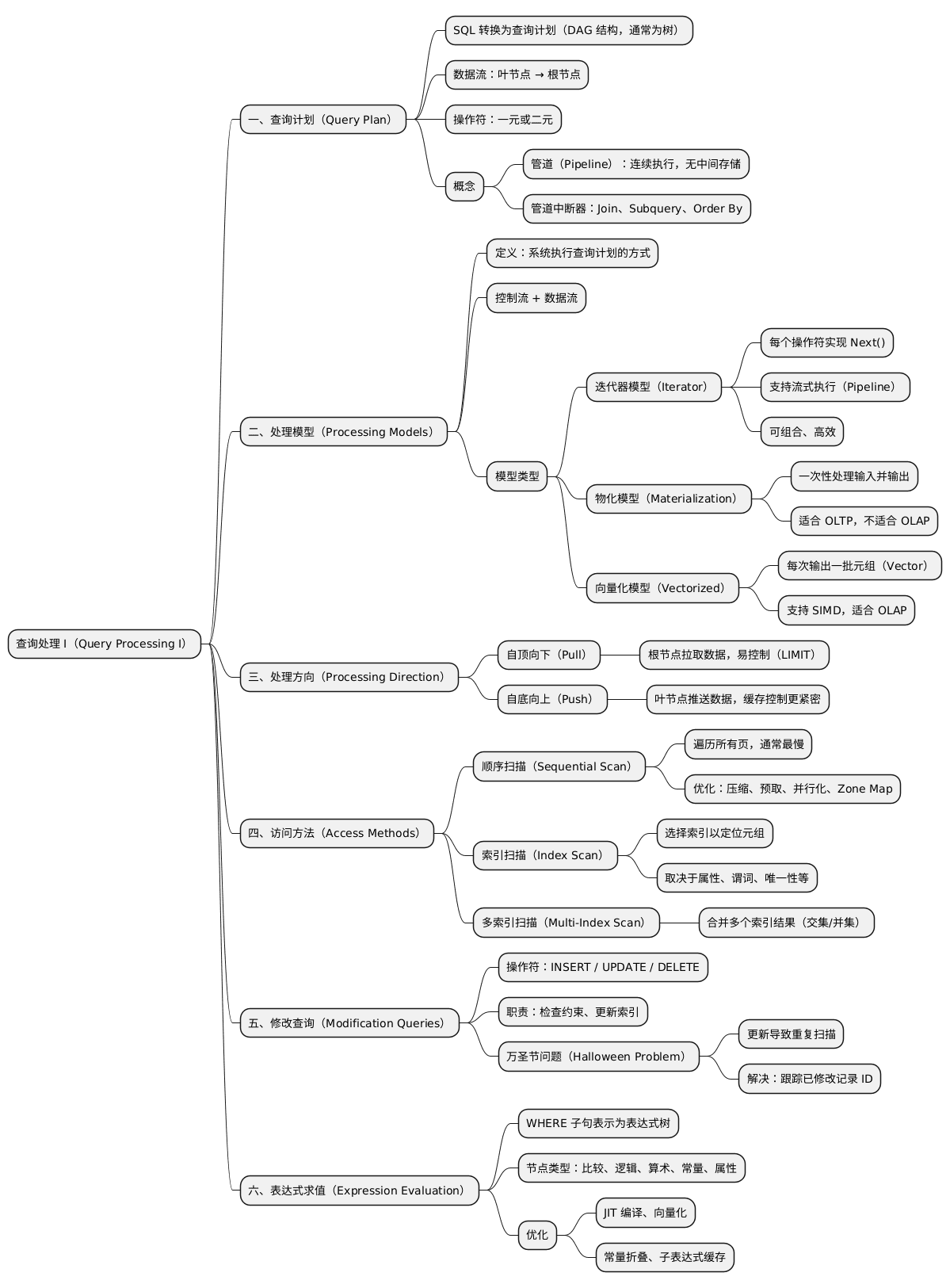
一、查询计划(Query Plan)
数据库管理系统(DBMS)会将 SQL 语句转换为查询计划(Query Plan)。
查询计划中的操作符(Operator)以有向无环图(DAG)的形式组织,通常呈树形结构。
- 数据流向:从叶节点向根节点流动;
- 根节点输出:整个查询的最终结果;
- 操作符类型:一般为一元或二元(即有一到两个子节点);
- 执行方式:同一个查询计划可以有多种执行策略。
管道(Pipeline):一系列操作符构成的序列,其中元组可以连续地流动而无需中间存储。
管道中断器(Pipeline Breaker):必须等待其所有子节点输出完毕才能执行的操作符,例如:
- 连接(Join)构建端;
- 子查询(Subquery);
- 排序(Order By)。
二、处理模型(Processing Models)
DBMS 的处理模型定义了系统如何执行查询计划,包括:
每种模型由两部分组成:
- 控制流(Control Flow):决定 DBMS 如何调用操作符;
- 数据流(Data Flow):决定操作符如何传递结果。
操作符输出的形式可能为:
- 整个元组(NSM,N-ary Storage Model);
- 列子集(DSM,Decomposition Storage Model)。
我们考虑的三种执行模型
- 迭代器模型(Iterator Model)
- 物化模型(Materialization Model)
- 向量化 / 批处理模型(Vectorized / Batch Model)
(一)迭代器模型(Iterator Model)
又称为 Volcano 模型 或 管道模型(Pipeline Model),是最常见的查询执行模型。
- 几乎所有基于行存储的数据库系统都使用它;
- 每个操作符实现一个
Next() 函数;
- 除叶节点外,父节点通过调用子节点的
Next() 获取元组;
- 每次调用
Next(),子节点返回一个元组或空标记;
- 元组被逐层传递、处理,直至根节点输出。
特点
- 高度可组合性;
- 各操作符可独立实现,只需遵守
Next() 接口;
- 对磁盘型系统效率高,因可最大化内存利用。
优点
- 支持流式执行(Pipelining);
- 易于控制输出(如 LIMIT 操作);
- 操作符可随时停止请求更多元组。
图 1:迭代器模型伪代码示例
各操作符的 Next() 本质上是一个循环,从子节点获取元组并向上返回。当所有元组被处理完毕后,会返回一个空指针或标记,告知父节点继续执行。
(二)物化模型(Materialization Model)
物化模型是迭代器模型的特殊化版本。每个操作符一次性处理全部输入并一次性输出所有结果。
- 不再逐个元组返回;
- 每次调用返回整个结果集;
- 适用于 OLTP(事务型负载);
- 对 OLAP(分析型负载)则效率较低,因为中间结果可能会溢出到磁盘。
每个操作符实现一个 Output() 函数:
- 一次性处理所有子操作符的元组;
- 返回所有结果元组。
图 2:物化模型示意图
从根节点开始调用 child.Output(),依次触发下层操作符,最终返回完整结果。
(三)向量化模型(Vectorization Model)
该模型与迭代器模型类似,但每个操作符在 Next() 调用中返回一批数据(Vector/Batch),而非单个元组。
- 内部循环针对批量处理进行了优化;
- 批量大小可根据硬件或查询特性动态调整;
- 减少函数调用次数;
- 便于使用 SIMD(单指令多数据)指令。
图 3:向量化模型示例
每个操作符对比输出缓冲区大小与期望批次大小,当缓冲区足够大时,将整批元组上推。
优势:
- 适合需要扫描大量元组的 OLAP 查询;
- 利用现代 CPU 的向量化能力;
- 无数据或控制依赖,循环紧凑且高效。
三、处理方向(Processing Direction)
操作符调用可采用两种方向:
方式一:自顶向下(Top-to-Bottom / Pull)
- 从根节点开始,逐级“拉取”数据;
- 元组通过函数调用传递;
- 易于控制(如 LIMIT);
- 父节点需等待子节点返回;
Next() 函数实现为虚函数会带来开销;- 每次调用可能产生分支成本。
方式二:自底向上(Bottom-to-Top / Push)
- 从叶节点开始,逐级“推送”数据;
- 更好地控制缓存和寄存器;
- 但难以精确控制中间结果规模;
- 某些迭代器难以在此模式下实现。
四、访问方法(Access Methods)
访问方法定义了 DBMS 如何从表中访问数据。
这些方法在关系代数中没有定义,因为它们属于物理层的实现。
三种基本方式
- 顺序扫描(Sequential Scan)
- 索引扫描(Index Scan)
- 多索引扫描(Multi-Index Scan)
(一)顺序扫描(Sequential Scan)
顺序遍历表中的所有页面,并从缓冲池中读取。
- 对每个页面上的元组评估谓词;
- 决定是否将元组传递给下一个操作符;
- 维护内部游标以跟踪当前页面和槽位。
该方法通常是最慢的,但有多种优化手段:
优化技术
- 压缩:使用 RLE(行程长度编码)等;
- 预取:提前加载若干页面,减少 I/O 阻塞;
- 缓冲池绕过:直接将页面存入本地内存;
- 并行化:多线程/多进程扫描;
- 延迟物化(Late Materialization):在列存中延迟拼接;
- 堆聚类(Heap Clustering):按聚类索引顺序存储;
- 结果缓存 / 物化视图;
- 代码编译 / JIT 优化;
- 近似查询(Approximate Query);
- 区域映射(Zone Map):预计算页级聚合以跳过无关页。
图 4:Zone Map 示例
每页维护最值信息。若查询条件超出页内最大值范围,可直接跳过该页。
(二)索引扫描(Index Scan)
DBMS 选择合适的索引以定位查询目标元组。
图 5:索引扫描示例
若表中有 age 和 department 索引,具体选择取决于谓词匹配度。
影响索引选择的因素
- 索引包含的属性;
- 查询引用的属性;
- 属性的值域;
- 谓词组合;
- 键的唯一性。
(三)多索引扫描(Multi-Index Scan)
高级 DBMS 支持使用多个索引联合扫描。
系统会:
- 计算各索引匹配的记录 ID 集;
- 对这些集合进行交集或并集操作;
- 获取对应记录并应用剩余谓词。
图 6:多索引扫描示例
先使用两个索引(如年龄和部门)分别筛选记录,再求交集,并对剩余条件(如 country='US')过滤。
五、修改查询(Modification Queries)
用于修改数据的操作符(INSERT, UPDATE, DELETE)需:
- 检查约束;
- 更新相关索引;
- 对
UPDATE / DELETE 操作,需传递记录 ID 并追踪已处理元组。
两种 INSERT 实现方式:
- 在操作符内部生成元组;
- 插入来自子操作符传递的元组。
万圣节问题(Halloween Problem)
更新操作改变了元组的物理位置,导致扫描器多次访问同一元组。
首次由 IBM 在 1976 年 System R 项目中发现。
解决方法:跟踪每个查询的修改记录 ID。
六、表达式求值(Expression Evaluation)
WHERE 子句在 DBMS 中表示为 表达式树(Expression Tree)。
图 7:表达式树示例
展示 WHERE 子句及其对应的逻辑表达结构。
表达式节点类型示例
- 比较(=, <, >, !=);
- 逻辑(AND, OR);
- 算术(+, -, *, /, %);
- 常量与参数;
- 元组属性引用。
运行时评估
- DBMS 维护执行上下文(包含当前元组、参数、模式等);
- 遍历表达式树逐个求值;
- 逐节点运算并生成结果。
性能问题:树形遍历对 CPU 效率低。
优化方法:
- JIT 编译:动态生成机器码直接计算;
- 向量化执行:批量评估多个元组;
- 常量折叠(Constant Folding):预先计算固定表达式;
- 子表达式限制(Subexpression Limitation):缓存重复子表达式结果。