15445-12-JoinAlgorithms
发布于 • 作者: Ethan
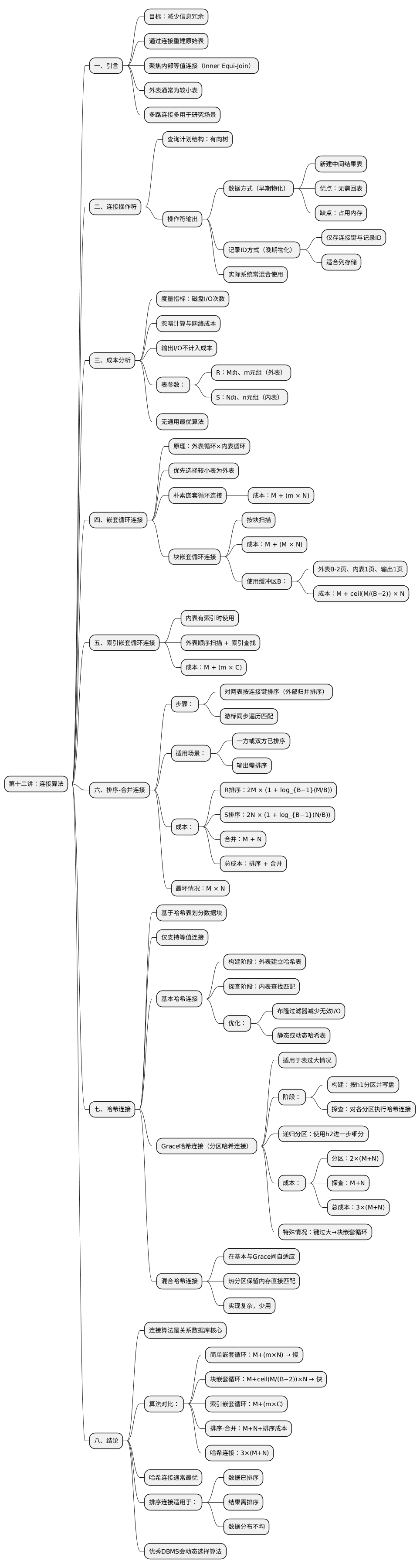
关系数据库设计通常利用规范化理论来减少冗余,因此查询中经常需要通过连接(Join)来恢复逻辑上的“原始表”。在实际系统中,最核心也最需要优化的是等值连接(Equijoin),尤其是自然连接。
连接算法众多,没有单一算法在所有场景中都最优,因此现代 DBMS 会根据数据规模、索引情况、排序情况、内存大小等动态选择策略。
连接算子位于查询执行树中间位置,其输出会成为后续算子的输入。连接两个元组 r ∈ R 与 s ∈ S 时,典型的输出是将二者拼接为新的元组。
示例: 假设要连接 Students(id, name, major) 与 Enroll(id, course, grade),若连接结果还需 GROUP BY,那么提前物化能减少重复回表读取。
示例: 在分析型数据库中,只需要 join key + RID,后续算子会按需从列存取真正需要的列,减少 I/O。
设:
注意:输出结果的 I/O 不计入比较,因为所有算法输出量相同。
对外表每个元组,扫描内表所有元组。
成本: [ M + mN ]
示例: 外表 1 万条数据,内表 100 万条数据,则需要比较约 (10^4 \times 10^6 = 10^{10}) 次,非常低效。
基于数据页而非元组比较,将外表按“页块”加载,从而减少内表扫描次数。
成本: [ M + M \times N ]
若使用 B 个 buffer frame,并把外表缓存成 B−2 页块: [ M + \left\lceil \frac{M}{B-2} \right\rceil N ]
示例:
若内表 join key 上已有索引,则外表逐条查 probe。
成本: [ M + mC ] 其中 C = 每次索引查找成本。
示例: 若内表 S 的 join key 有 B+Tree 索引,并假设一次查找平均需 3 I/O,则 m=10万 时需 30万 次 I/O,远小于扫描式的 m×N。
排序成本(外排序算法):
对于 R: [ 2M\left(1 + \left\lceil \log_{B-1} \left\lceil \frac{M}{B} \right\rceil \right\rceil \right) ] 对于 S:同理
合并成本: [ M + N ]
**最坏情况:**若所有 join key 完全相同,则退化为 M×N,因为每页都需与对方全部比较。
若 R=1000 页,S=500 页,B=100:
排序 R 成本:4000 I/O 排序 S 成本:2000 I/O 合并成本:1500 I/O 总计:约 7500 I/O
适合以下场景:
注意: 只适用于 equi-join,因为哈希函数依赖相等性。
在构建阶段同时构造 Bloom Filter,用于过滤不可能匹配的内表元组,减少无效 I/O。
示例: 如果外表 join key 仅包含某些 ID 范围,Bloom Filter 可直接让许多内表元组无需磁盘读取。
当内存不足以容纳整个外表哈希表时,需要分区处理。
[ 3(M+N) ]
示例: R 和 S 各 1GB,内存仅 100MB,则需将数据分为多个 100MB 以下的分区,并逐个处理。
若某些 join key 过于频繁(热点 key),可保留热点 bucket 在内存中即时处理,避免多次溢写到磁盘。
| 算法 | 成本(I/O) | 适用场景 |
|---|---|---|
| 简单 NLJ | M + mN | 小表与大表 join,小表作为外表 |
| 块 NLJ | M + ⌈M/(B−2)⌉N | 无索引、中等规模表 |
| 索引 NLJ | M + mC | 内表 join key 有索引 |
| Sort-Merge Join | M+N+排序开销 | 数据已排序或结果需要排序 |
| Hash Join | 3(M+N) | 最常见最稳定的 equi-join 方案 |
示例解读: 在课堂示例(M=1000,N=500 …)中,哈希连接是最快的(0.45 秒),sort-merge 次之(0.75 秒),NLJ 最慢。
连接算法是数据库系统性能的关键环节,各算法有其最优场景:
现代 DBMS(如 PostgreSQL、MySQL、DuckDB)会根据统计信息自动选择最优策略,并在必要时使用混合技术(如哈希 + Bloom Filter)。